Content from ¿Por qué usar un clúster?
Última actualización: 2026-03-31 | Mejora esta página
Hoja de ruta
Preguntas
- ¿Por qué debería interesarme la Computación de Alto Rendimiento (HPC)?
- ¿Qué puedo esperar aprender de este curso?
Objetivos
- Describir qué es un sistema HPC
- Identificar cómo un sistema HPC podría beneficiarlo.
Frecuentemente, los problemas de investigación que utilizan computación pueden superar las capacidades de la computadora de escritorio o laptop donde comenzaron:
- Un estudiante de estadística quiere hacer una validación cruzada (cross-validation) de un modelo. Esto implica ejecutar el modelo 1000 veces — pero cada ejecución toma una hora. Esto hará que ejecutar el modelo en una laptop tome más de un mes. En este problema de investigación, los resultados finales se calculan después de que se hayan ejecutado los 1000 modelos, pero normalmente solo se ejecuta un modelo a la vez (en serie) en la laptop. Dado que cada una de las 1000 ejecuciones es independiente de todas las demás, y si tuviéramos suficientes computadoras, es teóricamente posible ejecutarlas todas a la vez (en paralelo).
- Un investigador en genómica ha estado utilizando conjuntos de datos pequeños de secuencias, pero pronto recibirá un nuevo tipo de datos de secuenciación que es 10 veces más grande. De por sí, ya es un desafío abrir estos conjuntos de datos en una computadora; y realizar análisis con él probablemente la bloqueará. En este problema de investigación, los cálculos requeridos podrían ser imposibles de paralelizar, pero se necesitaría una computadora con más memoria para analizar el conjunto de datos mucho más grande en el futuro.
- Un ingeniero está utilizando un paquete de dinámica de fluidos que tiene una opción para ejecutarse en paralelo. Hasta ahora, no ha tenido la necesidad de usar esta opción en su computadora de escritorio. Sin embargo, al pasar de simulaciones 2D a 3D, el tiempo de simulación se ha más que triplicado. Por lo tanto sería útil aprovechar esa opción o característica. En este problema de investigación, los cálculos en cada región de la simulación son en gran medida independientes de los cálculos en otras regiones de la simulación. Es posible ejecutar los cálculos de cada región simultáneamente (en paralelo), comunicar resultados seleccionados a las regiones adyacentes según sea necesario, y repetir los cálculos para converger en un conjunto final de resultados. Al pasar de un modelo 2D a uno 3D, tanto la cantidad de datos como la cantidad de cálculos aumenta considerablemente, y es teóricamente posible distribuir los cálculos entre múltiples computadoras que se encuentren comunicadas a través de una red compartida.
En todos estos casos, se necesita el acceso a más computadoras (y más grandes). Esas computadoras deberían ser capaces de ser utilizadas al mismo tiempo, resolviendo muchos problemas de investigadores en paralelo.
Presentación Jargon Busting
Abra la presentación HPC Jargon
Buster en una nueva pestaña. Para presentar el contenido, primero
presione C para abrir un clon en una
ventana separada, y luego presione P para cambiar al modo
de presentación.
Nunca he usado un servidor, ¿Debería usar uno?
Tómate un minuto y piensa en cuáles de tus interacciones diarias con una computadora pueden requerir un servidor remoto o incluso un clúster para proporcionarte resultados.
- Revisar el correo electrónico: tu computadora (posiblemente en tu bolsillo) se conecta a una máquina remota, se autentica y descarga una lista de nuevos mensajes; también sube cambios en el estado de los mensajes (si los leíste, los marcaste como spam o los eliminaste). Dado que tu cuenta no es la única, el servidor de correo probablemente sea uno de muchos en un centro de datos.
- Realizar una búsqueda en línea implica comparar tu término de búsqueda con una base de datos masiva de todos los sitios conocidos, buscando coincidencias. Esta operación de “consulta” puede ser sencilla, pero construir esa base de datos es una tarea monumental. Los servidores están involucrados en cada paso.
- Buscar direcciones en un sitio web de mapas implica conectar tus puntos (A) de inicio y (B) de destino mediante el recorrido de un grafo en busca de la ruta “más corta” por distancia, tiempo, costo u otra métrica. Convertir un mapa a un grafo es relativamente simple, sin embargo, calcular todas las rutas posibles entre A y B es costoso.
Revisar el correo electrónico podría ser serial: tu máquina se conecta a un servidor y intercambia datos. Realizar una consulta a una base de datos por tu término de búsqueda (o palabras clave) también podría ser serial, en el sentido de que una máquina recibe tu consulta y devuelve el resultado. Sin embargo, el ensamble y almacenamiento de la base de datos completa escapa de la capacidad de cualquier máquina individual. Por lo tanto, estas funciones se sirven de una gran colección de servidores “hiperescalables” trabajando juntos.
- La Computación de Alto Rendimiento (HPC en inglés, High Performance Computing) típicamente implica conectarse a sistemas de computación muy grandes que se encuentran en cualquier parte del mundo.
- Estos sistemas pueden usarse para realizar trabajos que serían imposibles o mucho más lentos de completar en sistemas más pequeños.
- Los recursos HPC son compartidos por múltiples usuarios.
- El método estándar de interacción con dichos sistemas es a través de una interfaz de línea de comandos.
Content from Conectándose a un sistema HPC remoto
Última actualización: 2026-03-31 | Mejora esta página
Hoja de ruta
Preguntas
- ¿Cómo inicio sesión en un sistema HPC remoto?
Objetivos
- Configurar el acceso seguro a un sistema HPC remoto.
- Conectarse a un sistema HPC remoto.
Conexiones Seguras
El primer paso para usar un clúster es establecer una conexión desde nuestra laptop al clúster. Cuando estamos sentados frente a una computadora (o de pie, o sosteniéndola en nuestras manos o en nuestras muñecas), esperamos una pantalla visual con iconos, widgets y quizás algunas ventanas o aplicaciones: una interfaz gráfica de usuario, o GUI. Dado que los clústeres de computadoras son recursos remotos que se conectan a través de interfaces lentas o intermitentes (especialmente WiFi y VPN), es más práctico usar una interfaz de línea de comandos, o CLI, para enviar comandos como texto plano. Si un comando devuelve resultados, también se imprimen como texto plano. Los comandos que ejecutaremos hoy no abrirán una ventana para mostrar resultados gráficos.
Si alguna vez has abierto el Símbolo del Sistema (cmd)
de Windows o la Terminal de macOS, entonces has visto una CLI. Si has
tomado los cursos de The Carpentries sobre la Shell de UNIX o
Control de Versiones, tambien has usado la CLI en tu máquina
local extensamente. La diferencia es que ahora abrirás una CLI en
una máquina remota, tomando algunas precauciones para que otras
personas en la red no puedan ver (o cambiar) los comandos que estás
ejecutando o los resultados que la máquina remota envía de vuelta. Para
ello usaremos el protocolo Secure SHell (o SSH) para abrir una conexión
de red cifrada entre dos máquinas, lo que te permitirá enviar y recibir
texto y datos sin tener que preocuparte por ojos curiosos.

Los clientes SSH son generalmente herramientas de la línea de
comandos, donde proporcionas la dirección de la máquina remota como
único argumento obligatorio. Sin embargo, si el nombre de usuario en el
sistema remoto difiere del que usas localmente, también deberás
proporcionarlo. Si tu cliente SSH tiene una interfaz gráfica, como PuTTY
o MobaXterm, configurarás estos argumentos antes de hacer clic en
“conectar”. Desde la terminal, escribirás algo como
ssh userName@hostname, donde el argumento del comando es
parecido a una dirección de correo electrónico: el símbolo “@” se usa
para separar el nombre de usuario de la dirección de la máquina
remota.
Cuando inicias sesión en una laptop, tablet u otro dispositivo
personal, normalmente se requiere un nombre de usuario, contraseña o
patrón para evitar el acceso no autorizado. En estas situaciones, la
probabilidad de que alguien más intercepte tu contraseña es baja, ya que
registrar tus pulsaciones de teclas requiere una explotación maliciosa o
acceso físico. Para sistemas como login1 que ejecutan un
servidor SSH, cualquiera en la red puede iniciar sesión o intentarlo.
Dado que los nombres de usuario a menudo son públicos o fáciles de
adivinar, tu contraseña suele ser el eslabón más débil en la cadena de
seguridad. A modo de mejorar la seguridad, muchos clústeres prohíben el
inicio de sesión basado en contraseñas, requiriendo en su lugar que
generes y configures un par de claves públicas-privadas con una
contraseña mucho más fuerte. Incluso si tu clúster no lo requiere, la
siguiente sección te guiará a través del uso de claves SSH y un agente
SSH para fortalecer tu seguridad y facilitar el inicio de
sesión en sistemas remotos.
Mejor Seguridad con Claves SSH
En la sección de Configuración proporciona instrucciones de cómo instalar una aplicación de terminal con SSH. Si no lo has hecho aún, abre una terminal con una línea de comandos similar a Unix en tu sistema.
Las llaves SSH son un método alternativo de autenticación para obtener acceso a sistemas de computación remotos. También pueden usarse para autenticar la transferencia de archivos o para acceder a sistemas de control de versiones remotos (como GitHub). En esta sección crearás un par de claves SSH:
- una llave privada que guardas en tu propio computador, y
- una llave pública que puedes colocar en cualquier sistema remoto al que accedas.
Las llaves privadas son tu pasaporte digital seguro
Una llave privada que sea visible para cualquiera excepto tú debe considerarse comprometida, y debe ser destruida. Esto incluye tener permisos incorrectos en el directorio donde está almacenada (o una copia de él), atravesar cualquier red que no sea segura (cifrada), adjuntarla en correos electrónicos no cifrados, y hasta mostrarla en tu terminal.
Protege esta llave como si fuera la que abre la puerta principal de tu casa. En muchos sentidos, lo hace.
Independientemente del programa o sistema operativo que uses, por favor elige una contraseña corta o una larga fuerte que actúe como una capa de protección adicional para tu llave privada SSH.
Consideraciones para las Contraseñas de las Llaves SSH
Cuando se te solicite, introduce una contraseña segura que puedas recordar. Hay dos enfoques comunes para hacerlo:
- Crea una contraseña larga memorable con algunos signos de puntuación y sustituciones de números por letras, de 32 caracteres o más. Las direcciones de calle funcionan bien; solo ten cuidado con ataques de ingeniería social o registros públicos.
- Usa un gestor de contraseñas y su generador de contraseñas integrado con todas las clases de caracteres, de 25 caracteres o más. KeePass y BitWarden son dos buenas opciones.
- Nada es menos seguro que una llave privada sin contraseña. Si omitiste la entrada de contraseña por accidente, vuelve atrás y genera un nuevo par de llaves con una contraseña fuerte.
Llaves SSH en Linux, Mac, MobaXterm, y Windows Subsystem for Linux
Una vez que has abierto una terminal, comprueba si ya existen llaves SSH y sus nombres ya que las llaves existentes serán sobreescritas.
Si ~/.ssh/id_ed25519 ya existe, tendrás que especificar
un nombre diferente para el nuevo par de claves.
Genera un nuevo par de claves pública y privada utilizando el
siguiente comando, que producirá una clave más robusta que la
configuración predeterminada de ssh-keygen al emplear estas
opciones:
-
-a(valor predeterminado es 16): número de rondas de derivación de la contraseña; aumenta para ralentizar los ataques de fuerza bruta. -
-t(valor predeterminado es rsa): especifica el “tipo” o algoritmo criptográfico.ed25519especifica EdDSA con una clave de 256 bits; es más rápido que RSA con una fuerza comparable. -
-f(valor predeterminado es /home/user/.ssh/id_algorithm): nombre del archivo donde se almacenará tu llave privada. El nombre de la llave pública será idéntico, con la extensión.pubañadida.
Cuando se te solicite, introduce una contraseña segura con las consideraciones anteriores en mente. Ten en cuenta que la terminal no parecerá cambiar mientras escribes la contraseña: esto es intencional, por tu seguridad. Se te pedirá que la escribas nuevamente, así que no te preocupes demasiado por errores de escritura.
Echa un vistazo en ~/.ssh (usa ls ~/.ssh).
Deberías ver dos archivos nuevos:
- tu llave privada (
~/.ssh/id_ed25519): no la compartas con nadie! - la llave pública compartible (
~/.ssh/id_ed25519.pub): si un administrador del sistema te pide una llave, esta es la que debes enviar. Tambien es seguro subirla a sitios como GitHub: está pensada para ser vista.
Usa RSA para sistemas antiguos
Si la generacion de llaves falló porque ed25519 no está disponible, intenta usar el criptosistema RSA, auque es más antiguo aun es fuerte y confiable. De nuevo, primero verifica si ya existe una llave:
Si ~/.ssh/id_rsa ya existe, tendrás que elegir un nombre
distinto para el nuevo par de llaves. Genérala como arriba, con estas
opciones extra:
-
-bdefine el número de bits en la llave. El valor predeterminado es 2048. EdDSA usa una longitud fija, por lo que esta opción no tendría efecto. -
-o(sin valor predeterminado): usa el formato de llave OpenSSH, en lugar de PEM.
Cuando se te solicite, introduce una contraseña fuerte con las consideraciones anteriores en mente.
Echa un vistazo en ~/.ssh (usa ls ~/.ssh).
Deberías ver dos archivos nuevos:
- tu llave privada (
~/.ssh/id_rsa): no la compartas con nadie! - la llave pública compartible (
~/.ssh/id_rsa.pub): si un administrador del sistema te pide una llave, esta es la que debes enviar. Tambien es seguro subirla a sitios como GitHub: está pensada para ser vista.
Llaves SSH en PuTTY
Si usas PuTTY en Windows, descarga y utiliza puttygen
para generar el par de llaves. Consulta la documentación
de PuTTY para más detalles.
- Selecciona
EdDSAcomo tipo de llave. - Selecciona
255como tamaño o fuerza de llave. - Haz clic en el boton “Generate”.
- No necesitas introducir un comentario.
- Cuando se te solicite, introduce una contraseña fuerte con las consideraciones anteriores en mente.
- Guarda las llaves en una carpeta que otros usuarios del sistema no puedan leer.
Echa un vistazo en la carpeta que especificaste. Deberías ver dos archivos nuevos:
- tu llave privada (
id_ed25519): no la compartas con nadie! - la llave pública compartible (
id_ed25519.pub): si un administrador del sistema te pide una llave, esta es la que debes enviar. Tambien es seguro subirla a sitios como GitHub: está pensada para ser vista.
Agente SSH para un manejo mas sencillo de llaves
Una llave SSH es tan fuerte como la contraseña usada para desbloquearla, pero por otro lado, escribir una contraseña compleja cada vez que te conectas a una máquina es tedioso y se vuelve pesado muy rápido. Aquí es donde entra el Agente SSH.
Usando un Agente SSH, puedes escribir la contraseña de la llave privada una vez y luego el Agente la recuerda por cierto número de horas o hasta que cierres sesion. A menos que un actor malintencionado tenga acceso físico a tu máquina, esta herramienta mantiene tu contraseña segura y evita la molestia de ingresarla varias veces.
Solo recuerda tu contraseña, porque cuando expire en el Agente, tendrás que escribirla de nuevo.
Agentes SSH en Linux, macOS y Windows
Abre tu aplicación de terminal y comprueba si hay un agente ejecutándose:
-
Si obtienes un error como este,
ERROR
Error connecting to agent: No such file or directory… entonces necesitas iniciar el agente de la siguiente forma:
AvisoQue hay en un
$(...)?La sintaxis de este comando de Agente SSH es inusual, según lo visto en la lección de Shell de UNIX. Esto se debe a que el comando
ssh-agentcrea una conexión a la que solo tú tienes acceso e imprime una serie de comandos de shell que pueden usarse para alcanzarla, pero no los ejecuta!SALIDA
SSH_AUTH_SOCK=/tmp/ssh-Zvvga2Y8kQZN/agent.131521; export SSH_AUTH_SOCK; SSH_AGENT_PID=131522; export SSH_AGENT_PID; echo Agent pid 131522;El comando
evalinterpreta esta salida de texto como comandos y te permite acceder a la conexión del Agente SSH que acabas de crear.Podrías ejecutar cada línea de la salida de
ssh-agentpor tu cuenta y lograrás el mismo resultado. Usarevalsolo lo hace más fácil. En caso contrario, si tu agente ya está ejecutándose: no lo modifiques.
Agrega tu llave al agente, con expiración de sesión después de 8 horas:
SALIDA
Enter passphrase for .ssh/id_ed25519:
Identity added: .ssh/id_ed25519
Lifetime set to 86400 secondsDurante ese periodo (8 horas), cada vez que uses esa llave, el Agente SSH la proporcionará por ti sin que tengas que teclear una sola vez.
Agente SSH en PuTTY
Si usas PuTTY en Windows, descarga y utiliza pageant
como agente SSH. Consulta la documentación
de PuTTY.
Transfiere tu Llave Pública
Visit https://mokey.cluster.hpc-carpentry.org
to upload your SSH public key. (Remember, it’s the one ending in
.pub!)
Inicia sesión en el cluster
Abre tu terminal o cliente SSH gráfico y luego inicia sesión en el
cluster. Reemplaza yourUsername con tu nombre de usuario o
el proporcionado por el equipo instructor.
Puede que se te pida la contraseña. Cuidado: los caracteres que
escribes tras el mensaje de contraseña no se muestran en la pantalla. La
salida normal volverá una vez que presiones Enter.
Puede que hayas notado que el prompt cambió cuando iniciaste sesión
en el sistema remoto usando la terminal (si iniciaste sesión con PuTTY
esto no aplica porque no ofrece una terminal local). Este cambio es
importante porque ayuda a distinguir en que sistema se ejecutaran los
comandos que escribes. Este cambio también es una pequeña complicación
que tendremos que manejar durante el taller. Lo que se muestra como
prompt (que normalmente termina en $) en la terminal cuando
está conectada al sistema local y al remoto suele ser diferente para
cada usuario. Aun así, necesitamos indicar en qué sistema se introducen
los comandos, por lo que adoptaremos la siguiente convención:
-
[you@laptop:~]$cuando el comando se introduce en una terminal conectada a tu computadora local -
[yourUsername@login1 ~]$cuando el comando se introduce en una terminal conectada al sistema remoto -
$cuando en realidad no importa a que sistema esté conectada la terminal.
Explorando tu directorio personal remoto
A menudo, muchas personas tienden a pensar en una instalación de
computación de alto rendimiento como una sola máquina gigante y mágica.
A veces, se asume que la computadora en la que iniciaron sesión es todo
el cluster. Entonces, ¿qué está pasando realmente?, ¿a qué computadora
nos conectamos? El nombre de la computadora actual se puede comprobar
con el comando hostname. (Puede que notes que el hostname
actual también forma parte de nuestro prompt.)
SALIDA
Así que definitivamente estamos en la máquina remota. Ahora,
averiguemos donde estamos ejecutando pwd para
printar el directorio de trabajo.
SALIDA
/home/yourUsername¡Genial, sabemos donde estamos! Veamos qué hay en nuestro directorio actual:
SALIDA
id_ed25519.pubLos administradores del sistema pueden haber configurado tu directorio personal con archivos, carpetas y enlaces (accesos directos) útiles a espacios reservados para ti en otros sistemas de archivos. Si no lo hicieron, tu directorio personal puede verse vacío. Para comprobarlo, incluye archivos ocultos en el listado:
SALIDA
. .bashrc id_ed25519.pub
.. .sshEn la primera columna, . es una referencia al directorio
actual y .. a su directorio padre (/home).
Puede que veas o no los otros archivos, o archivos similares:
.bashrc es un archivo de configuracion de la shell, que
puedes editar con tus preferencias; y .ssh es un directorio
que guarda llaves SSH y un registro de conexiones autorizadas.
Instala tu llave SSH
Puede haber una mejor forma
Las políticas y prácticas para manejar llaves SSH varían entre clústeres HPC: sigue las indicaciones proporcionadas por las personas administradoras o la documentación. En particular, si hay un portal en línea para gestionar llaves SSH, usa eso en lugar de las instrucciones aquí descritas.
Si transferiste tu llave pública SSH con scp, deberias
ver id_ed25519.pub en tu directorio personal. Para
“instalar” esta llave, debe estar listada en un archivo llamado
authorized_keys dentro de la carpeta .ssh.
Si la carpeta .ssh no apareció arriba, entonces aun no
existe: créala.
Ahora, usa cat para mostrar tu llave pública, pero
redirige la salida y añádela al archivo
authorized_keys:
¡Eso es todo! Desconéctate y luego intenta iniciar sesión de nuevo en el remoto: si tu llave y el agente se configuraron correctamente, no se te pedirá la contraseña de tu llave SSH.
- Un sistema HPC es un conjunto de máquinas conectadas en red.
- Los sistemas HPC normalmente proporcionan nodos de acceso y un conjunto de nodos de trabajo.
- Los recursos en nodos independientes (de trabajo) pueden variar en volumen y tipo (cantidad de RAM, arquitectura de procesador, disponibilidad de sistemas de archivos montados en red, etc.).
- Los archivos guardados en un nodo están disponibles en todos los nodos.
Content from Trabajando en un sistema HPC remoto
Última actualización: 2026-03-31 | Mejora esta página
Hoja de ruta
Preguntas
- “¿Qué es un sistema HPC?”
- “¿Cómo funciona un sistema HPC?”
- “¿Cómo inicio sesión en un sistema HPC remoto?”
Objetivos
- “Conectarse a un sistema HPC remoto.”
- “Comprender la arquitectura general de un sistema HPC.”
¿Qué es un sistema HPC?
Las palabras “nube”, “clúster” y la frase “computación de alto rendimiento” o “HPC” se usan mucho en distintos contextos y con varios significados relacionados. Entonces, ¿qué significan? Y más importante, ¿cómo las usamos en nuestro trabajo?
La nube es un término genérico que suele referirse a recursos de cómputo que a) se aprovisionan a las personas usuarias bajo demanda o según necesidad y b) representan recursos reales o virtuales que pueden estar ubicados en cualquier lugar del mundo. Por ejemplo, una empresa grande con recursos de cómputo en Brasil, Zimbabue y Japón puede gestionar esos recursos como su nube interna y esa misma empresa puede también utilizar recursos de nube comerciales provistos por Amazon o Google. Los recursos de nube pueden referirse a máquinas que realizan tareas relativamente simples como servir sitios web, proporcionar almacenamiento compartido, ofrecer servicios web (como correo electrónico o plataformas de redes sociales), así como tareas de cómputo más intensivas como ejecutar una simulación.
El término sistema HPC, por otro lado, describe un recurso independiente para cargas de trabajo computacionalmente intensivas. Por lo general están compuestos por una multitud de elementos integrados de procesamiento y almacenamiento, diseñados para manejar grandes volúmenes de datos y/o un gran número de operaciones de punto flotante (FLOPS) con el mayor rendimiento posible. Por ejemplo, todas las máquinas de la lista Top-500 son sistemas HPC. Para cumplir estas restricciones, un recurso HPC debe existir en una ubicación específica y fija: los cables de red solo pueden extenderse hasta cierto punto, y las señales eléctricas y ópticas solo pueden viajar a cierta velocidad.
La palabra “clúster” se usa a menudo para recursos HPC de escala pequeña a moderada, menos impresionantes que el Top-500. Los clústeres suelen mantenerse en centros de cómputo que soportan varios sistemas de este tipo, todos compartiendo red y almacenamiento comunes para apoyar tareas de cómputo intensivas.
Iniciar sesión
El primer paso para usar un clúster es establecer una conexión desde nuestra laptop al clúster. Cuando estamos sentados frente a una computadora (o de pie, o sosteniéndola en las manos o en la muñeca), esperamos una pantalla visual con iconos, widgets y quizá algunas ventanas o aplicaciones: una interfaz gráfica de usuario, o GUI. Como los clústeres de computadoras son recursos remotos a los que nos conectamos mediante interfaces a menudo lentas o con retraso (especialmente WiFi y VPN), es más práctico usar una interfaz de línea de comandos, o CLI, en la que comandos y resultados se transmiten solo como texto. Cualquier cosa distinta al texto (por ejemplo, imágenes) debe escribirse en disco y abrirse con un programa separado.
Si alguna vez has abierto el Símbolo del Sistema de Windows o la Terminal de macOS, has visto una CLI. Si ya tomaste los cursos de The Carpentries sobre la Shell de UNIX o Control de Versiones, has usado la CLI en tu máquina local de manera relativamente extensa. El único salto aquí es abrir una CLI en una máquina remota, tomando algunas precauciones para que otras personas en la red no puedan ver (o cambiar) los comandos que estás ejecutando o los resultados que la máquina remota devuelve. Usaremos el protocolo Secure SHell (o SSH) para abrir una conexión de red cifrada entre dos máquinas, permitiéndote enviar y recibir texto y datos sin preocuparte por ojos curiosos.
Asegúrate de tener un cliente SSH instalado en tu laptop. Consulta la
sección de configuración para más detalles. Los
clientes SSH suelen ser herramientas de línea de comandos, donde
proporcionas la dirección de la máquina remota como el único argumento
obligatorio. Si tu nombre de usuario en el sistema remoto difiere del
que usas localmente, también debes proporcionarlo. Si tu cliente SSH
tiene una interfaz gráfica, como PuTTY o MobaXterm, configurarás estos
argumentos antes de hacer clic en “connect”. Desde la terminal,
escribirás algo como ssh userName@hostname, donde el
símbolo “@” se usa para separar las dos partes de un mismo
argumento.
Abre tu terminal o cliente SSH gráfico y luego inicia sesión en el clúster usando tu nombre de usuario y la computadora remota a la que puedes acceder desde el exterior, cluster.hpc-carpentry.org.
Recuerda reemplazar yourUsername por tu nombre de
usuario o el proporcionado por las personas instructoras. Puede que se
te pida la contraseña. Cuidado: los caracteres que escribes después del
mensaje de contraseña no se muestran en la pantalla. La salida normal se
reanudará una vez que presiones Enter.
¿Dónde estamos?
A menudo, muchas personas tienden a pensar en una instalación de
cómputo de alto rendimiento como una sola máquina gigante y mágica. A
veces, se asume que la computadora en la que iniciaron sesión es todo el
clúster. Entonces, ¿qué está pasando realmente? ¿A qué computadora nos
conectamos? El nombre de la computadora actual se puede comprobar con el
comando hostname. (¡Puede que notes que el hostname actual
también forma parte de nuestro prompt!)
SALIDA
login1¿Qué hay en tu directorio personal?
Las personas administradoras del sistema pueden haber configurado tu
directorio personal con algunos archivos, carpetas y enlaces (accesos
directos) útiles a espacios reservados para ti en otros sistemas de
archivos. Echa un vistazo y mira qué puedes encontrar. Pista:
Los comandos de shell pwd y ls pueden ser
útiles. El contenido del directorio personal varía de una persona a
otra. Comenta con tus vecinos cualquier diferencia que notes.
La capa más profunda debería diferir: yourUsername es
solo tuyo. ¿Hay diferencias en la ruta en niveles superiores?
Si ambos tienen directorios vacíos, se verán idénticos. Si tú o tu vecino han usado el sistema antes, puede haber diferencias. ¿En qué están trabajando?
Usa pwd para printar la ruta del
directorio de trabajo:
Puedes ejecutar ls para
listar el contenido del directorio,
aunque es posible que no se muestre nada (si no se han proporcionado
archivos). Para asegurarte, usa la opción -a para mostrar
también los archivos ocultos.
Como mínimo, esto mostrará el directorio actual como .,
y el directorio padre como ...
Nodos
Las computadoras individuales que componen un clúster suelen llamarse nodos (aunque también escucharás que las llaman servidores, computadoras y máquinas). En un clúster hay distintos tipos de nodos para diferentes tareas. El nodo en el que estás ahora se llama nodo principal, nodo de acceso, o nodo de envío. Un nodo de acceso sirve como punto de entrada al clúster.
Como puerta de enlace, es adecuado para subir y descargar archivos, configurar software y ejecutar pruebas rápidas. En general, el nodo de acceso no debe usarse para tareas que consuman mucho tiempo o recursos. Debes estar atento a esto y consultar con el personal operador o la documentación de tu sitio para detalles de lo que está o no permitido. En estas lecciones evitaremos ejecutar trabajos en el nodo principal.
Nodos dedicados para transferencia
Si quieres transferir grandes cantidades de datos hacia o desde el clúster, algunos sistemas ofrecen nodos dedicados solo para transferencias. La razón es que transferencias grandes no deberían obstaculizar el funcionamiento del nodo de acceso para el resto. Consulta la documentación de tu clúster o su equipo de soporte para saber si hay un nodo de transferencia disponible. Como regla general, considera grandes todas las transferencias de más de 500 MB a 1 GB. Pero estos números cambian, por ejemplo, según la conexión de red tuya y del clúster u otros factores.
El trabajo real en un clúster lo realizan los nodos de trabajo (o nodos de cómputo). Los nodos de trabajo vienen en muchas formas y tamaños, pero en general están dedicados a tareas largas o difíciles que requieren muchos recursos de cómputo.
Toda interacción con los nodos de trabajo es manejada por un software especializado llamado planificador, gestor de colas o scheduler (el planificador usado en esta lección se llama Slurm). Más adelante aprenderemos a usar el planificador para enviar trabajos, pero por ahora también puede darnos más información sobre los nodos de trabajo.
Por ejemplo, podemos ver todos los nodos de trabajo ejecutando el
comando sinfo.
SALIDA
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST
cpubase_bycore_b1* up infinite 4 idle node[1-2],smnode[1-2]
node up infinite 2 idle node[1-2]
smnode up infinite 2 idle smnode[1-2]También hay máquinas especializadas que se usan para gestionar almacenamiento en disco, autenticación de usuarios y otras tareas de infraestructura. Aunque no solemos iniciar sesión ni interactuar directamente con estas máquinas, permiten funciones clave como asegurar que nuestra cuenta de usuario y archivos estén disponibles en todo el sistema HPC.
¿Qué hay en un nodo?
Todos los nodos en un sistema HPC tienen los mismos componentes que tu laptop o escritorio: CPU (a veces también llamadas procesadores o núcleos), memoria (o RAM) y espacio en disco. Las CPU son la herramienta de la computadora para ejecutar programas y cálculos. La información sobre una tarea actual se almacena en la memoria de la computadora. El disco se refiere a todo almacenamiento al que se puede acceder como sistema de archivos. Por lo general es almacenamiento que puede guardar datos de forma permanente, es decir, los datos siguen ahí incluso si la computadora se reinicia. Aunque este almacenamiento puede ser local (un disco duro instalado dentro del equipo), es más común que los nodos se conecten a un servidor de archivos compartido y remoto o a un clúster de servidores.
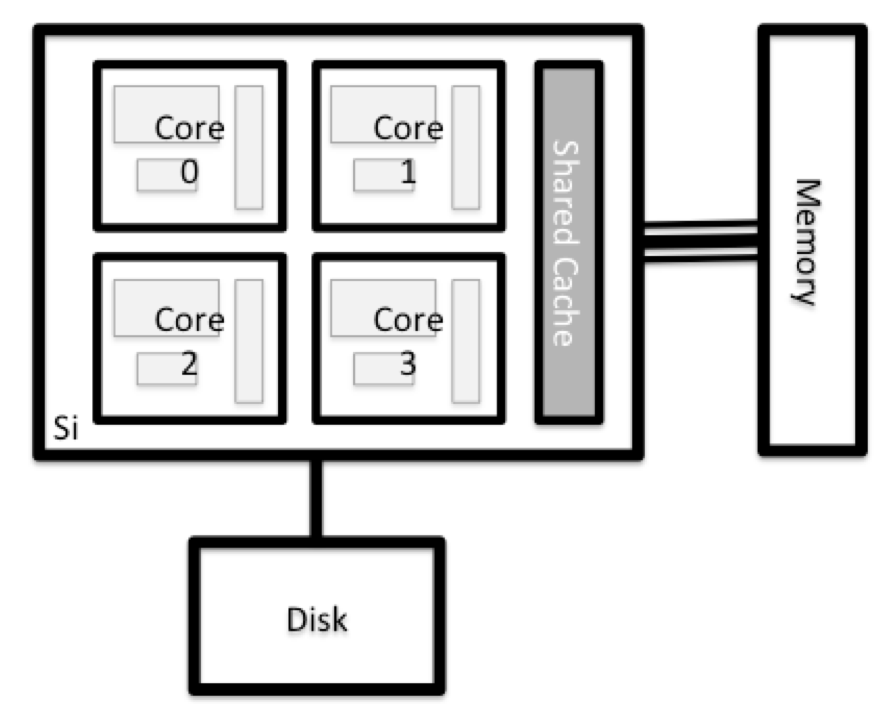
Hay varias maneras de hacer esto. La mayoría de los sistemas operativos tiene un monitor del sistema gráfico, como el Administrador de tareas de Windows. A veces se puede encontrar información más detallada en la línea de comandos. Por ejemplo, algunos de los comandos usados en un sistema Linux son:
Ejecuta utilidades del sistema
Lee desde /proc
Usa un monitor del sistema
Explora el nodo de acceso
Ahora compara los recursos de tu computadora con los del nodo de acceso.
BASH
[you@laptop:~]$ ssh yourUsername@cluster.hpc-carpentry.org
[yourUsername@login1 ~]$ nproc --all
[yourUsername@login1 ~]$ free -mPuedes obtener más información sobre los procesadores usando
lscpu, y muchos detalles sobre la memoria leyendo el
archivo /proc/meminfo:
También puedes explorar los sistemas de archivos disponibles usando
df para mostrar el espacio libre en
disco. La opción -h muestra los tamaños en
un formato legible, es decir, GB en lugar de B. La opción de
tipo -T indica qué tipo de sistema de
archivos es cada recurso.
Los sistemas de archivos locales (ext, tmp, xfs, zfs) dependerán de si estás en el mismo nodo de acceso (o nodo de cómputo, más adelante). Los sistemas de archivos en red (beegfs, cifs, gpfs, nfs, pvfs) serán similares, pero pueden incluir yourUsername, dependiendo de cómo esté montado.
Sistemas de archivos compartidos
Este es un punto importante para recordar: los archivos guardados en un nodo (computadora) a menudo están disponibles en todo el clúster.
Compara tu computadora, el nodo de acceso y el nodo de cómputo
Compara el número de procesadores y la memoria de tu laptop con los números que ves en el nodo principal del clúster y el nodo de trabajo. Comenta las diferencias con tu vecino.
¿Qué implicaciones crees que podrían tener esas diferencias al ejecutar tu trabajo de investigación en los distintos sistemas y nodos?
Diferencias entre nodos
Muchos clústeres HPC tienen una variedad de nodos optimizados para cargas de trabajo particulares. Algunos nodos pueden tener mayor cantidad de memoria, o recursos especializados como Unidades de Procesamiento Gráfico (GPU).
Con todo esto en mente, ahora veremos cómo hablar con el planificador del clúster y usarlo para empezar a ejecutar nuestros scripts y programas.
- “Un sistema HPC es un conjunto de máquinas conectadas en red.”
- “Los sistemas HPC normalmente proporcionan nodos de acceso y un conjunto de nodos de trabajo.”
- “Los recursos en nodos independientes (de trabajo) pueden variar en volumen y tipo (cantidad de RAM, arquitectura del procesador, disponibilidad de sistemas de archivos montados en red, etc.).”
- “Los archivos guardados en un nodo están disponibles en todos los nodos.”
Content from Fundamentos del Planificador de Trabajos
Última actualización: 2026-03-31 | Mejora esta página
Hoja de ruta
Preguntas
- ¿Qué es un planificador de trabajos y por qué lo necesita un clúster?
- ¿Cómo lanzo un programa para que se ejecute en un nodo de cómputo del clúster?
- ¿Cómo capturo la salida de un programa que se ejecuta en un nodo del clúster?
Objetivos
- Enviar un script simple al clúster.
- Monitorear la ejecución de trabajos usando herramientas de línea de comandos.
- Inspeccionar los archivos de salida y error de tus trabajos.
- Encontrar el lugar adecuado para poner conjuntos de datos grandes en el clúster.
Planificador de trabajos
Un sistema HPC puede tener miles de nodos y miles de usuarios. ¿Cómo decidimos quién obtiene qué y cuándo? ¿Cómo aseguramos que una tarea se ejecute con los recursos que necesita? Este trabajo lo realiza un software especial llamado gestor de colas o planificador. En un sistema HPC, el planificador gestiona qué trabajos se ejecutan, dónde y cuándo.
La siguiente ilustración compara estas tareas de un planificador de trabajos con un mesero en un restaurante. Si puedes relacionarlo con alguna ocasión en la que tuviste que esperar en una fila para entrar a un restaurante popular, entonces puedes entender por qué a veces tu trabajo no inicia de inmediato como en tu laptop.

El planificador usado en esta lección es Slurm. Aunque Slurm no se usa en todos lados, ejecutar trabajos es bastante similar sin importar el software que se utilice. La sintaxis exacta puede cambiar, pero los conceptos permanecen iguales.
Ejecutar un trabajo por lotes (batch)
El uso más básico del planificador es ejecutar un comando de forma no interactiva. Cualquier comando (o serie de comandos) que quieras ejecutar en el clúster se llama trabajo, y el proceso de usar un planificador para ejecutar el trabajo se llama envío de trabajos por lotes o batch job submission.
En este caso, el trabajo que queremos ejecutar es un script de shell: en esencia, un archivo de texto que contiene una lista de comandos UNIX que se ejecutan de manera secuencial. Nuestro script tendrá tres partes:
- En la primera línea, agrega
#!/bin/bash. El#!(pronunciado “hash-bang” o “shebang”) le dice a la computadora qué programa debe procesar el contenido de este archivo. En este caso, le indicamos que los comandos que siguen están escritos para la shell de línea de comandos (la que hemos estado usando hasta ahora). - En cualquier lugar debajo de la primera línea, agregaremos un
comando
echocon un saludo amistoso. Al ejecutarse, el script imprimirá en la terminal todo lo que venga después deecho.-
echo -nimprimirá todo lo que sigue, sin terminar la línea con el carácter de nueva línea.
-
- En la última línea, invocaremos el comando
hostname, que imprimirá el nombre de la máquina donde se ejecuta el script.
Creando nuestro trabajo de prueba
Ejecuta el script. ¿Se ejecuta en el clúster o solo en nuestro nodo de acceso?
Este script se ejecutó en el nodo de acceso, pero queremos aprovechar
los nodos de cómputo: necesitamos que el planificador ponga
example-job.sh en cola para ejecutarlo en un nodo de
cómputo.
Para enviar esta tarea al planificador, usamos el comando
sbatch. Esto crea un trabajo que ejecutará el
script cuando sea despachado a un nodo de cómputo que
el sistema de colas ha identificado como disponible para realizar el
trabajo.
SALIDA
Submitted batch job 7Y eso es todo lo que necesitamos para enviar un trabajo. Nuestro
trabajo está hecho: ahora el planificador se encarga y trata de
ejecutarlo por nosotros. Mientras el trabajo espera para ejecutarse,
entra en una lista de trabajos llamada cola. Para revisar el
estado del trabajo, consultamos la cola con el comando
squeue -u yourUsername.
SALIDA
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
9 cpubase_b example- user01 R 0:05 1 node1Podemos ver todos los detalles de nuestro trabajo, y lo más
importante es que está en estado R o RUNNING.
A veces nuestros trabajos deben esperar en la cola
(PENDING) o presentar un error (E).
¿Dónde está la salida?
En el nodo de acceso, este script imprimió la salida en la terminal,
pero ahora, cuando squeue muestra que el trabajo terminó,
no se imprimió nada en la terminal.
La salida de un trabajo en el clúster normalmente se redirige a un
archivo en el directorio desde el que lo lanzaste. Usa ls
para encontrarlo y cat para leerlo.
Personalizar un trabajo
El trabajo que acabamos de ejecutar usó todas las opciones predeterminadas del planificador. En un escenario real, probablemente no es lo que queremos. Las opciones predeterminadas representan un mínimo razonable. Es probable que necesitemos más núcleos, más memoria, más tiempo, entre otras consideraciones especiales. Para acceder a esos recursos debemos personalizar nuestro script.
Los comentarios en scripts de shell UNIX (marcados con
#) normalmente se ignoran, pero hay excepciones. Por
ejemplo, el comentario especial #! al inicio de los scripts
especifica qué programa debe usarse para ejecutarlo (normalmente verás
#!/bin/bash). Planificadores como Slurm también tienen un
comentario especial que se usa para indicar opciones específicas del
planificador. Aunque estos comentarios difieren entre planificadores, el
comentario especial de Slurm es #SBATCH. Cualquier cosa que
siga al comentario #SBATCH se interpreta como una
instrucción al planificador.
Ilustremos esto con un ejemplo. Por defecto, el nombre de un trabajo
es el nombre del script, pero la opción -J se puede usar
para cambiar el nombre de un trabajo. Agrega una opción al script:
Envía el trabajo y monitorea su estado:
SALIDA
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
10 cpubase_b hello-wo user01 R 0:02 1 node1¡Excelente, cambiamos con éxito el nombre de nuestro trabajo!
Solicitudes de recursos
¿Qué hay de cambios más importantes, como el número de núcleos y la memoria para nuestros trabajos? Algo absolutamente crítico cuando trabajamos en un sistema HPC es especificar los recursos necesarios para ejecutar un trabajo. Esto permite que el planificador encuentre el momento y el lugar adecuados para programar nuestro trabajo. Si no especificas requisitos (como el tiempo que necesitas), probablemente quedarás limitado a los recursos predeterminados de tu sitio, lo cual no es lo que deseas.
Estas son algunas solicitudes clave de recursos:
--ntasks=<ntasks>o-n <ntasks>: ¿Cuántos núcleos de CPU necesita tu trabajo en total?--time <days-hours:minutes:seconds>o-t <days-hours:minutes:seconds>: ¿Cuánto tiempo real (walltime) tardará en ejecutarse tu trabajo? La parte<days>se puede omitir.--mem=<megabytes>: ¿Cuánta memoria en un nodo necesita tu trabajo en megabytes? También puedes especificar gigabytes añadiendo una “g” después (ejemplo:--mem=5g)--nodes=<nnodes>o-N <nnodes>: ¿En cuántas máquinas separadas necesita ejecutarse tu trabajo? Ten en cuenta que si establecesntasksen un número mayor que lo que puede ofrecer una sola máquina, Slurm ajustará este valor automáticamente.
Ten en cuenta que solo solicitar estos recursos no hace que tu trabajo corra más rápido, ni significa necesariamente que consumirás todos esos recursos. Solo significa que se ponen a tu disposición. Tu trabajo puede terminar usando menos memoria, menos tiempo o menos nodos de los que solicitaste, y aun así se ejecutará.
Es mejor que tus solicitudes reflejen con precisión los requisitos de tu trabajo. Hablaremos más sobre cómo asegurarte de usar los recursos de manera efectiva en un episodio posterior de esta lección.
Enviar solicitudes de recursos
Modifica nuestro script hostname para que se ejecute
durante un minuto, y luego envía un trabajo para él en el clúster.
Las solicitudes de recursos suelen ser obligatorias. Si las excedes, tu trabajo será terminado. Usemos el tiempo de ejecución real (wall time) como ejemplo. Solicitaremos 1 minuto de tiempo real e intentaremos ejecutar un trabajo durante dos minutos.
BASH
#!/bin/bash
#SBATCH -J long_job
#SBATCH -t 00:01 # timeout in HH:MM
echo "This script is running on ... "
sleep 240 # time in seconds
hostnameEnvía el trabajo y espera a que termine. Una vez que haya terminado, revisa el archivo de registro.
SALIDA
This script is running on ...
slurmstepd: error: *** JOB 12 ON node1 CANCELLED AT 2021-02-19T13:55:57
DUE TO TIME LIMIT ***Nuestro trabajo fue terminado por exceder la cantidad de recursos solicitados. Aunque esto parezca duro, en realidad es una característica. El cumplimiento estricto de las solicitudes de recursos permite que el planificador encuentre el mejor lugar posible para tus trabajos. Aún más importante, asegura que otra persona usuaria no pueda usar más recursos de los que se le asignaron. Si otra persona se equivoca y accidentalmente intenta usar todos los núcleos o la memoria de un nodo, Slurm restringirá su trabajo a los recursos solicitados o lo terminará de inmediato. Los otros trabajos en el nodo no se verán afectados. Esto significa que una persona no puede arruinar la experiencia de las demás; los únicos trabajos afectados por un error en la planificación serán los suyos.
Cancelar un trabajo
A veces cometeremos un error y necesitaremos cancelar un trabajo.
Esto se puede hacer con el comando scancel. Enviemos un
trabajo y luego cancelémoslo usando su número de trabajo (recuerda
cambiar el tiempo de ejecución real (wall time) para que se
ejecute lo suficiente como para cancelarlo antes de que sea
terminado).
SALIDA
Submitted batch job 13
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
13 cpubase_b long_job user01 R 0:02 1 node1Ahora cancela el trabajo con su número (impreso en tu terminal). El retorno limpio del prompt indica que la solicitud de cancelación fue exitosa.
BASH
[yourUsername@login1 ~]$ scancel 38759
# It might take a minute for the job to disappear from the queue...
[yourUsername@login1 ~]$ squeue -u yourUsernameSALIDA
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)Cancelar múltiples trabajos
También podemos cancelar todos nuestros trabajos a la vez usando la
opción -u. Esto eliminará todos los trabajos de una persona
usuaria específica (en este caso, tú). Ten en cuenta que solo puedes
eliminar tus propios trabajos.
Intenta enviar varios trabajos y luego cancelarlos todos.
Otros tipos de trabajos
Hasta este punto, nos hemos enfocado en ejecutar trabajos en modo por
lotes (batch mode). Slurm también ofrece la
posibilidad de iniciar una sesión interactiva.
Con mucha frecuencia hay tareas que deben hacerse de forma
interactiva. Crear un script de trabajo completo puede ser excesivo,
pero la cantidad de recursos requerida es demasiada para un nodo de
acceso. Un buen ejemplo sería construir un índice genómico para
alineamiento con una herramienta como HISAT2. Por suerte,
podemos ejecutar este tipo de tareas de una sola vez con
srun.
srun ejecuta un solo comando en el clúster y luego sale.
Demostremos esto ejecutando el comando hostname con
srun. (Podemos cancelar un trabajo de srun con
Ctrl-c.)
SALIDA
smnode1srun acepta todas las mismas opciones que
sbatch. Sin embargo, en lugar de especificarlas en un
script, estas opciones se indican en la línea de comandos al iniciar un
trabajo. Por ejemplo, para enviar un trabajo que use 2 CPU, podríamos
usar el siguiente comando:
SALIDA
This job will use 2 CPUs.
This job will use 2 CPUs.Por lo general, el entorno de la shell resultante será el mismo que
el de sbatch.
Trabajos interactivos
A veces necesitarás muchos recursos para uso interactivo. Tal vez sea
nuestra primera vez ejecutando un análisis o estemos intentando depurar
algo que salió mal en un trabajo anterior. Afortunadamente, Slurm
facilita iniciar un trabajo interactivo con srun:
Deberías ver un prompt de bash. Observa que el prompt probablemente
cambiará para reflejar tu nueva ubicación, en este caso el nodo de
cómputo en el que estamos conectados. También puedes verificarlo con
hostname.
Crear gráficos remotos
Para ver salida gráfica dentro de tus trabajos, necesitas usar
reenvío X11. Para conectar con esta función habilitada, usa la opción
-X cuando inicies sesión con el comando ssh,
por ejemplo,
ssh -X yourUsername@cluster.hpc-carpentry.org.
Para demostrar lo que sucede cuando creas una ventana gráfica en el
nodo remoto, usa el comando xeyes. Debería aparecer un par
de ojos bastante adorables (presiona Ctrl-C para detener).
Si usas Mac, debes haber instalado XQuartz (y reiniciado tu computadora)
para que esto funcione.
Si tu clúster tiene instalado el plugin slurm-spank-x11,
puedes asegurar el reenvío X11 dentro de trabajos interactivos usando la
opción --x11 para srun con el comando
srun --x11 --pty bash.
Cuando termines con el trabajo interactivo, escribe exit
para salir de la sesión.
- El planificador gestiona cómo se comparten los recursos de cómputo entre usuarios.
- Un trabajo es solo un script de shell.
- Solicita ligeramente más recursos de los que necesitarás.
Content from Variables de Entorno
Última actualización: 2026-03-31 | Mejora esta página
Hoja de ruta
Preguntas
- ¿Cómo se establecen y acceden las variables en la shell de Unix?
- ¿Cómo puedo usar variables para cambiar cómo se ejecuta un programa?
Objetivos
- Entender cómo se implementan las variables de entorno en la shell.
- Leer el valor de una variable existente.
- Crear nuevas variables y cambiar sus valores.
- Cambiar el comportamiento de un programa usando una variable de entorno.
- Explicar cómo la shell usa la variable
PATHpara buscar ejecutables.
Origen del episodio
Este episodio ha sido remezclado a partir del episodio de Shell Extras sobre Variables de Shell y del episodio de HPC Shell sobre scripts.
La shell es solo un programa, y como otros programas, tiene variables. Esas variables controlan su ejecución, por lo que cambiando sus valores puedes cambiar cómo se comporta la shell (y con un poco más de esfuerzo cómo se comportan otros programas).
Las variables son una excelente manera de guardar información bajo un nombre que puedas acceder más tarde. En lenguajes de programación como Python y R, las variables pueden almacenar prácticamente cualquier cosa que imagines. En la shell, generalmente solo almacenan texto. La mejor manera de entender cómo funcionan es verlas en acción.
Comencemos ejecutando el comando set y observando
algunas de las variables en una sesión típica de shell:
SALIDA
COMPUTERNAME=TURING
HOME=/home/vlad
HOSTNAME=TURING
HOSTTYPE=i686
NUMBER_OF_PROCESSORS=4
PATH=/Users/vlad/bin:/usr/local/git/bin:/usr/bin:/bin:/usr/sbin:/sbin:/usr/local/bin
PWD=/home/vlad
UID=1000
USERNAME=vlad
...Como puedes ver, hay bastantes —de hecho, cuatro o cinco veces más
que lo que se muestra aquí. Y sí, usar set para
mostrar cosas puede parecer un poco extraño, incluso para Unix,
pero si no le das argumentos, bien podría mostrarte cosas que
podrías establecer.
Cada variable tiene un nombre. Los valores de todas las variables de
shell son cadenas de texto, incluso los que (como UID)
parecen números. Es responsabilidad de los programas convertir estas
cadenas a otros tipos cuando sea necesario. Por ejemplo, si un programa
quisiera averiguar cuántos procesadores tiene la computadora,
convertiría el valor de la variable NUMBER_OF_PROCESSORS de
una cadena a un entero.
Mostrar el valor de una variable
Mostremos el valor de la variable HOME:
SALIDA
HOMEEso solo imprime “HOME”, que no es lo que queremos (aunque es lo que realmente pedimos). Intentemos esto en lugar:
SALIDA
/home/vladEl signo de dólar le dice a la shell que queremos el valor
de la variable en lugar de su nombre. Esto funciona igual que los
comodines: la shell hace el reemplazo antes de ejecutar el
programa que pedimos. Gracias a esta expansión, lo que realmente
ejecutamos es echo /home/vlad, que muestra lo correcto.
Crear y cambiar variables
Crear una variable es fácil: simplemente asignamos un valor a un
nombre usando “=” (solo tenemos que recordar que la sintaxis requiere
que no haya ningún espacio alrededor de =):
SALIDA
DraculaPara cambiar el valor, simplemente asigna uno nuevo:
SALIDA
CamillaVariables de entorno
Cuando ejecutamos el comando set, vimos que había muchas
variables cuyos nombres estaban en mayúsculas. Eso es porque, por
convención, las variables que también están disponibles para que las
usen otros programas tienen nombres en mayúsculas. Tales
variables se llaman variables de entorno ya que son variables
de shell que se definen para la shell actual y son heredadas por
cualquier shell secundaria o proceso.
Para crear una variable de entorno necesitas export una
variable de shell. Por ejemplo, para que nuestra
SECRET_IDENTITY esté disponible para otros programas que
llamamos desde nuestra shell podemos hacer:
También puedes crear y exportar la variable en un solo paso:
Usar variables de entorno para cambiar el comportamiento del programa
Establece una variable de shell TIME_STYLE con un valor
de iso y verifica este valor usando el comando
echo.
Ahora, ejecuta el comando ls con la opción
-l (que da un formato largo).
export la variable y vuelve a ejecutar el comando
ls -l. ¿Notas alguna diferencia?
La variable TIME_STYLE no es vista por
ls hasta que es exportada, en cuyo punto ls la
usa para decidir qué formato de fecha usar al mostrar la marca de tiempo
de los archivos.
Puedes ver el conjunto completo de variables de entorno en tu sesión
de shell actual con el comando env (que devuelve un
subconjunto de lo que el comando set nos dio). El
conjunto completo de variables de entorno se llama tu entorno en
tiempo de ejecución y puede afectar el comportamiento de los
programas que ejecutas.
Variables de entorno de trabajo
Cuando Slurm ejecuta un trabajo, establece varias
variables de entorno para el trabajo. Una de estas nos permitirá
verificar desde qué directorio se envió nuestro script de trabajo. La
variable SLURM_SUBMIT_DIR se establece en el directorio
desde el que se envió nuestro trabajo. Usando la variable
SLURM_SUBMIT_DIR, modifica tu trabajo para que imprima la
ubicación desde la cual se envió el trabajo.
Para eliminar una variable o variable de entorno, puedes usar el
comando unset, por ejemplo:
La variable de entorno PATH
Del mismo modo, algunas variables de entorno (como PATH)
almacenan listas de valores. En este caso, la convención es usar dos
puntos ‘:’ como separador. Si un programa quiere los elementos
individuales de tal lista, es responsabilidad del programa dividir el
valor de cadena de la variable en partes.
Veamos de cerca esa variable PATH. Su valor define la
ruta de búsqueda de la shell para ejecutables, es decir, la lista de
directorios en que la shell busca programas ejecutables cuando escribes
un nombre de programa sin especificar en qué directorio está.
Por ejemplo, cuando escribimos un comando como analyze,
la shell necesita decidir si ejecutar ./analyze o
/bin/analyze. La regla que usa es simple: la shell verifica
cada directorio en la variable PATH por turno, buscando un
programa con el nombre solicitado en ese directorio. Tan pronto como
encuentra una coincidencia, detiene la búsqueda y ejecuta el
programa.
Para mostrar cómo funciona, aquí están los componentes de
PATH listados uno por línea:
SALIDA
/Users/vlad/bin
/usr/local/git/bin
/usr/bin
/bin
/usr/sbin
/sbin
/usr/local/binEn nuestra computadora, en realidad hay tres programas llamados
analyze en tres directorios diferentes:
/bin/analyze, /usr/local/bin/analyze y
/users/vlad/analyze. Como la shell busca los directorios en
el orden en que se enumeran en PATH, encuentra
/bin/analyze primero y lo ejecuta. Observa que
nunca encontrará el programa /users/vlad/analyze a
menos que escribas la ruta completa al programa, ya que el directorio
/users/vlad no está en PATH.
Esto significa que puedo tener ejecutables en muchos lugares
diferentes siempre que recuerde que necesito actualizar mi
PATH para que mi shell pueda encontrarlos.
¿Y si quiero ejecutar dos versiones diferentes del mismo programa?
Como comparten el mismo nombre, si agrego ambas a mi PATH,
la primera que se encuentre siempre ganará. En el próximo episodio
aprenderemos a usar herramientas auxiliares para ayudarnos a gestionar
nuestro entorno en tiempo de ejecución para hacer que eso sea posible
sin que necesitemos hacer mucha contabilidad sobre cuál es o debería ser
el valor de PATH (y otras variables de entorno
importantes).
- Las variables de shell se tratan como cadenas de texto por defecto.
- Las variables se asignan usando “
=” y se recuperan usando el nombre de la variable con el prefijo “$”. - Usa “
export” para que una variable esté disponible para otros programas. - La variable
PATHdefine la ruta de búsqueda de la shell.
Content from Acceder a software a través de Módulos
Última actualización: 2026-03-31 | Mejora esta página
Hoja de ruta
Preguntas
- ¿Cómo cargamos y descargamos paquetes de software?
Objetivos
- Cargar y usar un paquete de software.
- Explicar cómo cambia el entorno de la shell cuando el mecanismo de módulos carga o descarga paquetes.
En un sistema de computación de alto rendimiento, raramente el software que queremos usar está disponible cuando iniciamos sesión. Está instalado, pero necesitaremos “cargarlo” antes de que pueda ejecutarse.
Antes de empezar a usar paquetes de software individuales, sin embargo, debemos entender el razonamiento detrás de este enfoque. Los tres factores más grandes son:
- incompatibilidades de software
- versiones
- dependencias
La incompatibilidad de software es un dolor de cabeza importante para
los programadores. A veces, la presencia (o ausencia) de un paquete de
software romperá otros que dependen de él. Dos ejemplos bien conocidos
son las versiones de Python y compilador C. Python 3 proporciona
famosamente un comando python que entra en conflicto con el
proporcionado por Python 2. El software compilado contra una versión más
nueva de las bibliotecas C y luego ejecutado en una máquina que tiene
versiones más antiguas de bibliotecas C instaladas resultará en un error
opaco 'GLIBCXX_3.4.20' not found.
El versionado del software es otro problema común. Un equipo podría depender de una cierta versión del paquete para su proyecto de investigación; si la versión del software cambiara (por ejemplo, si se actualizara un paquete), podría afectar sus resultados. Tener acceso a múltiples versiones de software permite a un conjunto de investigadores evitar que los problemas de versiones de software afecten sus resultados.
Las dependencias son donde un paquete de software particular (o incluso una versión particular) depende de tener acceso a otro paquete de software (o incluso una versión particular de otro paquete de software). Por ejemplo, el software de ciencia de materiales VASP puede requerir una versión particular de la biblioteca de software FFTW (Transformada rápida de Fourier en el Oeste) para que funcione.
Módulos de entorno
Los módulos de entorno son la solución a estos problemas. Un módulo es una descripción autónoma de un paquete de software: contiene la configuración requerida para ejecutar un paquete de software y, generalmente, codifica las dependencias requeridas en otros paquetes de software.
Hay varias implementaciones diferentes de módulos de entorno
comúnmente usadas en sistemas HPC: las dos más comunes son módulos
TCL y Lmod. Ambos usan sintaxis similar y los conceptos
son los mismos, por lo que aprender a usar uno te permitirá usar el que
esté instalado en el sistema que estés usando. En ambas
implementaciones, el comando module se usa para interactuar
con módulos de entorno. Generalmente se agrega un subcomando adicional
al comando para especificar qué quieres hacer. Para una lista de
subcomandos puedes usar module -h o
module help. Como con todos los comandos, puedes acceder a
la ayuda completa en las páginas man con
man module.
Al iniciar sesión, puede que comiences con un conjunto predeterminado de módulos cargados o puede que comiences con un entorno vacío; esto depende de la configura del sistema que estés usando.
Listar módulos disponibles
Para ver módulos de software disponibles, usa
module avail:
SALIDA
~~~ /cvmfs/pilot.eessi-hpc.org/2020.12/software/x86_64/amd/zen2/modules/all ~~~
Bazel/3.6.0-GCCcore-x.y.z NSS/3.51-GCCcore-x.y.z
Bison/3.5.3-GCCcore-x.y.z Ninja/1.10.0-GCCcore-x.y.z
Boost/1.72.0-gompi-2020a OSU-Micro-Benchmarks/5.6.3-gompi-2020a
CGAL/4.14.3-gompi-2020a-Python-3.x.y OpenBLAS/0.3.9-GCC-x.y.z
CMake/3.16.4-GCCcore-x.y.z OpenFOAM/v2006-foss-2020a
[removed most of the output here for clarity]
Where:
L: Module is loaded
D: Default Module
Aliases exist: foo/1.2.3 (1.2) means that
"module load foo/1.2" will load foo/1.2.3
Use "module spider" to find all possible modules and extensions.
Use "module keyword key1 key2 ..." to search for all possible modules matching
any of the "keys".Ten en cuenta que enviar la salida a través de less nos
permite buscar dentro de la salida usando la tecla /.
Listar módulos cargados actualmente
Puedes usar el comando module list para ver qué módulos
tienes actualmente cargados en tu entorno. Si no tienes módulos
cargados, verás un mensaje que te lo dice.
SALIDA
Currently Loaded Modules:
1) autotools 3) gnu14/14.2.0 5) ucx/1.18.0 7) openmpi5/5.0.7 9) ohpc
2) prun/2.2 4) hwloc/2.12.0 6) libfabric/1.18.0 8) nvtop/3.2.0
Cargar y descargar software
Para cargar un módulo de software, usa module load.
En este ejemplo usaremos Python 3. Inicialmente, no está cargado.
Podemos probar esto usando el comando which.
which busca programas de la misma manera que Bash, así que
podemos usarlo para decirnos dónde se almacena un software
particular.
If the python3 command was unavailable, we would see
output like
SALIDA
/usr/bin/which: no python3 in (/cvmfs/pilot.eessi-hpc.org/2020.12/compat/linux/x86_64/usr/bin:/opt/software/slurm/bin:/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/opt/puppetlabs/bin:/home/yourUsername/.local/bin:/home/yourUsername/bin)Note that this wall of text is really a list, with values separated
by the : character. The output is telling us that the
which command searched the following directories for
python3, without success:
SALIDA
/cvmfs/pilot.eessi-hpc.org/2020.12/compat/linux/x86_64/usr/bin
/opt/software/slurm/bin
/usr/local/bin
/usr/bin
/usr/local/sbin
/usr/sbin
/opt/puppetlabs/bin
/home/yourUsername/.local/bin
/home/yourUsername/binHowever, in our case we do have an existing python3
available so we see
SALIDA
/cvmfs/pilot.eessi-hpc.org/2020.12/compat/linux/x86_64/usr/bin/python3We need a different Python than the system provided one though, so let us load a module to access it.
Podemos cargar el comando python3 con
module load:
SALIDA
/cvmfs/pilot.eessi-hpc.org/2020.12/software/x86_64/amd/zen2/software/Python/3.x.y-GCCcore-x.y.z/bin/python3Entonces, ¿qué acaba de suceder?
Para entender la salida, primero necesitamos entender la naturaleza
de la variable de entorno $PATH. $PATH es una
variable de entorno especial que controla dónde busca software un
sistema UNIX. Específicamente, $PATH es una lista de
directorios (separados por :) que el SO busca a través de
un comando antes de rendirse y decirnos que no puede encontrarlo. Como
con todas las variables de entorno, podemos imprimirlo usando
echo.
SALIDA
/opt/ohpc/pub/apps/spack/local/linux-x86_64/python-3.13.5-aloly4qhu2ecv2x3urosyr44oq4hmbn6/bin:/opt/ohpc/pub/apps/spack/local/linux-x86_64/gettext-0.23.1-qde2xzyizazzp5s47ejgaxyzwc4nfnfd/bin:/opt/ohpc/pub/apps/spack/local/linux-x86_64/libxml2-2.13.5-z4a4hmomjj5ro423f22s2t32zvlciycd/bin:/opt/ohpc/pub/apps/spack/local/linux-x86_64/tar-1.35-qe5dfed6ps3v2caxwfdwwqyah7z6pbu4/bin:/opt/ohpc/pub/apps/spack/local/linux-x86_64/pigz-2.8-2smh4ufgfif5rb3j6m2zkhrca3seaiqg/bin:/opt/ohpc/pub/apps/spack/local/linux-x86_64/bzip2-1.0.8-wucwh5ce7m7vilxnz56gwqxqzx7nnwzb/bin:/opt/ohpc/pub/apps/spack/local/linux-x86_64/zstd-1.5.7-shcfzlty5p73tnmstuv2rw5uil6y6qfh/bin:/opt/ohpc/pub/apps/spack/local/linux-x86_64/libiconv-1.18-446fnouxgsaesaumijbliacukhy3ixde/bin:/opt/ohpc/pub/apps/spack/local/linux-x86_64/sqlite-3.46.0-ugjl73lgudrl2prwuxinbqtx7j4lzrne/bin:/opt/ohpc/pub/apps/spack/local/linux-x86_64/openssl-3.4.1-zsrh72hcb4nifdxsddfhbylgofl2dp7x/bin:/opt/ohpc/pub/apps/spack/local/linux-x86_64/gdbm-1.23-hzp3jssy2pkph7kmjtqyonoqfpd6fhzu/bin:/opt/ohpc/pub/apps/spack/local/linux-x86_64/expat-2.7.1-zfeeeecjghhwg3sud4lnwk354hyyxava/bin:/opt/ohpc/pub/apps/spack/local/linux-x86_64/readline-8.2-2sa76zwjjun2hdt7cn75hmt6cutq3egw/bin:/opt/ohpc/pub/apps/spack/local/linux-x86_64/ncurses-6.5-24imdjdnnqyszfgfquu23k2jcumxzfv2/bin:/opt/ohpc/pub/apps/spack/local/linux-x86_64/xz-5.6.3-dfp5nxkcjqw55iyzxcg5vcvdud3z2jmw/bin:/opt/ohpc/pub/apps/spack/local/linux-x86_64/util-linux-uuid-2.41-mtu6n2jns45cggjd7x3y7c2bax7oaes5/bin:/usr/local/sbin:/opt/ohpc/pub/apps/nvtop/bin:/opt/ohpc/pub/mpi/libfabric/1.18.0/bin:/opt/ohpc/pub/mpi/ucx-ohpc/1.18.0/bin:/opt/ohpc/pub/libs/hwloc/bin:/opt/ohpc/pub/mpi/openmpi5-gnu14/5.0.7/bin:/opt/ohpc/pub/compiler/gcc/14.2.0/bin:/opt/ohpc/pub/utils/prun/2.2:/opt/ohpc/pub/utils/autotools/bin:/opt/ohpc/pub/bin:/usr/local/bin:/usr/bin:/usr/sbinNotarás una similitud con la salida del comando which.
En este caso, solo hay una diferencia: el directorio diferente está al
principio. Cuando ejecutamos el comando module load, se
agregó un directorio al principio de nuestra $PATH o se
“antepuso al $PATH”. Veamos qué hay allí:
BASH
[yourUsername@login1 ~]$ ls /cvmfs/pilot.eessi-hpc.org/2020.12/software/x86_64/amd/zen2/software/Python/3.x.y-GCCcore-x.y.z/binSALIDA
2to3 nosetests-3.8 python rst2s5.py
2to3-3.8 pasteurize python3 rst2xetex.py
chardetect pbr python3.8 rst2xml.py
cygdb pip python3.8-config rstpep2html.py
cython pip3 python3-config runxlrd.py
cythonize pip3.8 rst2html4.py sphinx-apidoc
easy_install pybabel rst2html5.py sphinx-autogen
easy_install-3.8 __pycache__ rst2html.py sphinx-build
futurize pydoc3 rst2latex.py sphinx-quickstart
idle3 pydoc3.8 rst2man.py tabulate
idle3.8 pygmentize rst2odt_prepstyles.py virtualenv
netaddr pytest rst2odt.py wheel
nosetests py.test rst2pseudoxml.pyEn resumen, module load agregará software a tu
$PATH. “Carga” software. Una nota importante al respecto:
dependiendo de qué versión del programa module esté
instalada en tu sistema, module load también cargará las
dependencias de software necesarias.
To demonstrate, let’s use module list.
module list shows all loaded software modules.
SALIDA
Currently Loaded Modules:
1) GCCcore/x.y.z 4) GMP/6.2.0-GCCcore-x.y.z
2) Tcl/8.6.10-GCCcore-x.y.z 5) libffi/3.3-GCCcore-x.y.z
3) SQLite/3.31.1-GCCcore-x.y.z 6) Python/3.x.y-GCCcore-x.y.zSALIDA
Currently Loaded Modules:
1) GCCcore/x.y.z 14) libfabric/1.11.0-GCCcore-x.y.z
2) Tcl/8.6.10-GCCcore-x.y.z 15) PMIx/3.1.5-GCCcore-x.y.z
3) SQLite/3.31.1-GCCcore-x.y.z 16) OpenMPI/4.0.3-GCC-x.y.z
4) GMP/6.2.0-GCCcore-x.y.z 17) OpenBLAS/0.3.9-GCC-x.y.z
5) libffi/3.3-GCCcore-x.y.z 18) gompi/2020a
6) Python/3.x.y-GCCcore-x.y.z 19) FFTW/3.3.8-gompi-2020a
7) GCC/x.y.z 20) ScaLAPACK/2.1.0-gompi-2020a
8) numactl/2.0.13-GCCcore-x.y.z 21) foss/2020a
9) libxml2/2.9.10-GCCcore-x.y.z 22) pybind11/2.4.3-GCCcore-x.y.z-Pytho...
10) libpciaccess/0.16-GCCcore-x.y.z 23) SciPy-bundle/2020.03-foss-2020a-Py...
11) hwloc/2.2.0-GCCcore-x.y.z 24) networkx/2.4-foss-2020a-Python-3.8...
12) libevent/2.1.11-GCCcore-x.y.z 25) GROMACS/2020.1-foss-2020a-Python-3...
13) UCX/1.8.0-GCCcore-x.y.zSo in this case, loading the GROMACS module (a
bioinformatics software package), also loaded
GMP/6.2.0-GCCcore-x.y.z and
SciPy-bundle/2020.03-foss-2020a-Python-3.x.y as well. Let’s
try unloading the GROMACS package.
SALIDA
Currently Loaded Modules:
1) GCCcore/x.y.z 13) UCX/1.8.0-GCCcore-x.y.z
2) Tcl/8.6.10-GCCcore-x.y.z 14) libfabric/1.11.0-GCCcore-x.y.z
3) SQLite/3.31.1-GCCcore-x.y.z 15) PMIx/3.1.5-GCCcore-x.y.z
4) GMP/6.2.0-GCCcore-x.y.z 16) OpenMPI/4.0.3-GCC-x.y.z
5) libffi/3.3-GCCcore-x.y.z 17) OpenBLAS/0.3.9-GCC-x.y.z
6) Python/3.x.y-GCCcore-x.y.z 18) gompi/2020a
7) GCC/x.y.z 19) FFTW/3.3.8-gompi-2020a
8) numactl/2.0.13-GCCcore-x.y.z 20) ScaLAPACK/2.1.0-gompi-2020a
9) libxml2/2.9.10-GCCcore-x.y.z 21) foss/2020a
10) libpciaccess/0.16-GCCcore-x.y.z 22) pybind11/2.4.3-GCCcore-x.y.z-Pytho...
11) hwloc/2.2.0-GCCcore-x.y.z 23) SciPy-bundle/2020.03-foss-2020a-Py...
12) libevent/2.1.11-GCCcore-x.y.z 24) networkx/2.4-foss-2020a-Python-3.x.ySo using module unload “un-loads” a module, and
depending on how a site is configured it may also unload all of the
dependencies (in our case it does not). If we wanted to unload
everything at once, we could run module purge (unloads
everything).
SALIDA
No modules loadedNote that module purge is informative. It will also let
us know if a default set of “sticky” packages cannot be unloaded (and
how to actually unload these if we truly so desired).
Ten en cuenta que este proceso de carga de módulos sucede
principalmente a través de la manipulación de variables de entorno como
$PATH. Generalmente hay poco o ningún movimiento de datos
involucrado.
El proceso de carga de módulos también manipula otras variables de entorno especiales, incluidas variables que influyen en dónde busca el sistema bibliotecas de software, y a veces variables que le dicen a paquetes de software comercial dónde encontrar servidores de licencia.
El comando module también restaura estas variables de entorno de la shell a su estado anterior cuando un módulo se descarga.
Versioning del software
Hasta ahora, hemos aprendido cómo cargar y descargar paquetes de software. Esto es muy útil. Sin embargo, aún no hemos abordado el problema del versionado del software. En algún momento u otro, te encontrarás con problemas donde solo una versión particular de algún software será adecuada. Quizá la corrección de un error clave solo sucedió en una versión determinada, o la versión X rompió la compatibilidad con un formato de archivo que usas. En cualquiera de estos casos de ejemplo, es útil ser muy específico sobre qué versión de software estas cargado.
Examinemos la salida de module avail más de cerca,
usando el paginador ya que puede haber montones de salida:
SALIDA
~~~ /cvmfs/pilot.eessi-hpc.org/2020.12/software/x86_64/amd/zen2/modules/all ~~~
Bazel/3.6.0-GCCcore-x.y.z NSS/3.51-GCCcore-x.y.z
Bison/3.5.3-GCCcore-x.y.z Ninja/1.10.0-GCCcore-x.y.z
Boost/1.72.0-gompi-2020a OSU-Micro-Benchmarks/5.6.3-gompi-2020a
CGAL/4.14.3-gompi-2020a-Python-3.x.y OpenBLAS/0.3.9-GCC-x.y.z
CMake/3.16.4-GCCcore-x.y.z OpenFOAM/v2006-foss-2020a
[removed most of the output here for clarity]
Where:
L: Module is loaded
D: Default Module
Aliases exist: foo/1.2.3 (1.2) means that
"module load foo/1.2" will load foo/1.2.3
Use "module spider" to find all possible modules and extensions.
Use "module keyword key1 key2 ..." to search for all possible modules matching
any of the "keys".Si el software que ejecuta tu script de Slurm requiere una versión
específica de una dependencia, asegúrate de utilizar el nombre completo
del módulo, en lugar de la versión predeterminada (default) que
se carga cuando se indica solo su nombre (hasta la primera barra
/)
Usar módulos de software en scripts
Crea un trabajo que pueda ejecutar python3 --version.
Recuerda, ¡ningún software está cargado por defecto! Ejecutar un trabajo
es como iniciar sesión en el sistema (no debes asumir que un módulo
cargado en el nodo de acceso está cargado en un nodo de cómputo).
BASH
[yourUsername@login1 ~]$ nano python-module.slurm
[yourUsername@login1 ~]$ cat python-module.slurmSALIDA
#!/bin/bash
#SBATCH
#SBATCH -t 00:00:30
module load Python
python3 --versionEs recomendable guardar tus scripts de trabajo con la extensión
.slurm, ya que así podrás diferenciarlos fácilmente de los
scripts de shell tradicionales.
- Carga software con
module load nombreDelSoftware. - Descarga software con
module unload. - El sistema de módulos gestiona automáticamente el versionado del software y los conflictos entre paquetes.
Content from Transferencia de archivos con computadoras remotas
Última actualización: 2026-03-31 | Mejora esta página
Hoja de ruta
Preguntas
- ¿Cómo transfiero archivos hacia (y desde) el clúster?
Objetivos
- Transferir archivos hacia y desde un clúster de cómputo.
Trabajar en una computadora remota no es muy útil si no podemos obtener archivos hacia o desde él. Hay varias opciones para transferir datos entre recursos de cómputo usando herramientas CLI y GUI, algunas de las cuales cubriremos.
Descargar archivos de la lección desde Internet
Una de las formas más directas de descargar archivos es usar
curl o wget. Uno de estos suele estar
instalado en la mayoría de las shells de Linux, en la terminal de macOS
y en GitBash. Cualquier archivo que pueda descargarse en tu navegador
web mediante un enlace directo puede descargarse usando
curl o wget. Esta es una forma rápida de
descargar conjuntos de datos o código fuente. La sintaxis de estos
comandos es
wget [-O new_name] https://some/link/to/a/filecurl [-o new_name] https://some/link/to/a/file
Pruébalo descargando algo del material que usaremos más adelante, desde una terminal en tu máquina local, usando la URL del código base actual:
https://github.com/hpc-carpentry/amdahl/tarball/main
Descargar el “tarball”
La palabra “tarball” en la URL anterior se refiere a un formato de
archivo comprimido comúnmente usado en Linux, que es el sistema
operativo en el que corre la mayoría de las máquinas de los clústeres
HPC. Un tarball es muy parecido a un archivo .zip. La
extensión real del archivo es .tar.gz, que refleja el
proceso de dos etapas usado para crear el archivo: los archivos o
carpetas se combinan en un solo archivo con tar, que luego
se comprime con gzip, por lo que la extensión del archivo
es “tar-punto-g-z”. Es un trabalenguas, así que la gente suele decir “el
tarball xyz”.
También puedes ver la extensión .tgz, que es solo una
abreviatura de .tar.gz.
De forma predeterminada, curl y wget
descargan archivos con el mismo nombre que la URL: en este caso,
main. Usa uno de los comandos anteriores para guardar el
tarball como amdahl.tar.gz.
Después de descargar el archivo, usa ls para verlo en tu
directorio de trabajo:
Archivar archivos
Uno de los mayores desafíos que enfrentamos al transferir datos entre sistemas HPC remotos es el gran número de archivos. Existe una sobrecarga al transferir cada archivo individual y, cuando transferimos grandes cantidades de archivos, esas sobrecargas se combinan y ralentizan nuestras transferencias en gran medida.
La solución a este problema consiste en archivar múltiples
archivos en un número menor de archivos, pero más grandes, antes de
transferir los datos. Esto con el fin de mejorar la eficiencia de la
transferencia. En ocasiones, combinaremos la creación de archivos con
compresión para reducir la cantidad de datos a transferir y así
acelerar el proceso. El comando de archivado más común que se utiliza en
un clúster HPC (Linux) es tar.
tar puede usarse para combinar archivos y carpetas en un
solo archivo y, opcionalmente, comprimir el resultado. Veamos el archivo
que descargamos del sitio de la lección, amdahl.tar.gz.
La parte .gz significa gzip, que es una
biblioteca de compresión. Es común (¡aunque no necesario!) que este tipo
de archivo pueda interpretarse leyendo su nombre: parece que alguien
tomó archivos y carpetas relacionados con algo llamado “amdahl”, los
empaquetó en un solo archivo con tar, y luego comprimió ese
archivo con gzip para ahorrar espacio.
Veamos si ese es el caso, sin descomprimir el archivo.
tar imprime la “tabla de contenidos” con
la opción -t, para el archivo especificado con la opción
-f seguida del nombre del archivo. Ten en cuenta que puedes
concatenar las dos opciones: escribir -t -f es
intercambiable con escribir -tf junto. Sin embargo, el
argumento que sigue a -f debe ser un nombre de archivo, así
que escribir -ft no funcionará.
BASH
[you@laptop:~]$ tar -tf amdahl.tar.gz
hpc-carpentry-amdahl-46c9b4b/
hpc-carpentry-amdahl-46c9b4b/.github/
hpc-carpentry-amdahl-46c9b4b/.github/workflows/
hpc-carpentry-amdahl-46c9b4b/.github/workflows/python-publish.yml
hpc-carpentry-amdahl-46c9b4b/.gitignore
hpc-carpentry-amdahl-46c9b4b/LICENSE
hpc-carpentry-amdahl-46c9b4b/README.md
hpc-carpentry-amdahl-46c9b4b/amdahl/
hpc-carpentry-amdahl-46c9b4b/amdahl/__init__.py
hpc-carpentry-amdahl-46c9b4b/amdahl/__main__.py
hpc-carpentry-amdahl-46c9b4b/amdahl/amdahl.py
hpc-carpentry-amdahl-46c9b4b/requirements.txt
hpc-carpentry-amdahl-46c9b4b/setup.pyEste ejemplo de salida muestra una carpeta que contiene algunos
archivos, donde 46c9b4b es un hash de commit de git de 8 caracteres
que cambiará cuando el material fuente se actualice.
Ahora descomprimamos el archivo. Ejecutaremos tar con
algunas opciones comunes:
-
-xpara extraer el archivo -
-vpara salida verbosa -
-zpara compresión gzip -
-f «tarball»para el archivo a descomprimir
Extraer el archivo
Usando las opciones anteriores, descomprime el tarball del código
fuente en un nuevo directorio llamado “amdahl” usando
tar.
SALIDA
hpc-carpentry-amdahl-46c9b4b/
hpc-carpentry-amdahl-46c9b4b/.github/
hpc-carpentry-amdahl-46c9b4b/.github/workflows/
hpc-carpentry-amdahl-46c9b4b/.github/workflows/python-publish.yml
hpc-carpentry-amdahl-46c9b4b/.gitignore
hpc-carpentry-amdahl-46c9b4b/LICENSE
hpc-carpentry-amdahl-46c9b4b/README.md
hpc-carpentry-amdahl-46c9b4b/amdahl/
hpc-carpentry-amdahl-46c9b4b/amdahl/__init__.py
hpc-carpentry-amdahl-46c9b4b/amdahl/__main__.py
hpc-carpentry-amdahl-46c9b4b/amdahl/amdahl.py
hpc-carpentry-amdahl-46c9b4b/requirements.txt
hpc-carpentry-amdahl-46c9b4b/setup.pyTen en cuenta que no necesitamos escribir -x -v -z -f,
gracias a la concatenación de opciones, aunque el comando funciona igual
de cualquier forma, siempre y cuando la lista concatenada termine con
f, porque la siguiente cadena debe especificar el nombre
del archivo a extraer.
La carpeta tiene un nombre poco conveniente, así que cambiémoslo por algo más práctico.
Verifica el tamaño del directorio extraído y compáralo con el tamaño
del archivo comprimido, usando du para “uso de disco”
(disk usage).
BASH
[you@laptop:~]$ du -sh amdahl.tar.gz
8.0K amdahl.tar.gz
[you@laptop:~]$ du -sh amdahl
48K amdahlLos archivos de texto (incluyendo el código fuente de Python) se comprimen bien: ¡el “tarball” es una sexta parte del tamaño total de los datos en bruto!
Si quieres invertir el proceso, comprimiendo datos en bruto en lugar
de extraerlos, usa la opción c en lugar de x,
indica el nombre del archivo y luego proporciona un directorio para
comprimir:
SALIDA
amdahl/
amdahl/.github/
amdahl/.github/workflows/
amdahl/.github/workflows/python-publish.yml
amdahl/.gitignore
amdahl/LICENSE
amdahl/README.md
amdahl/amdahl/
amdahl/amdahl/__init__.py
amdahl/amdahl/__main__.py
amdahl/amdahl/amdahl.py
amdahl/requirements.txt
amdahl/setup.pySi proporcionas amdahl.tar.gz como nombre de archivo en
el comando anterior, tar actualizará el tarball existente
con cualquier cambio que hayas hecho en los archivos. Eso significaría
agregar la nueva carpeta amdahl a la carpeta
existente (hpc-carpentry-amdahl-46c9b4b) dentro
del tarball, ¡duplicando el tamaño del archivo!
Trabajar con Windows
Cuando transfieres archivos de texto desde un sistema Windows a un sistema Unix (Mac, Linux, BSD, Solaris, etc.), esto puede causar problemas. Windows codifica sus archivos de forma ligeramente diferente a Unix y agrega un carácter extra en cada línea.
En un sistema Unix, cada línea de un archivo termina con un
\n (nueva línea). En Windows, cada línea termina con un
\r\n (retorno de carro (carriage return) + nueva
línea). Esto a veces causa problemas.
Aunque la mayoría de los lenguajes de programación y software
modernos manejan esto correctamente, en algunos casos raros puedes
encontrarte con un problema. La solución es convertir un archivo de
codificación Windows a Unix con el comando dos2unix.
Puedes identificar si un archivo tiene finales de línea de Windows
con cat -A filename. Un archivo con finales de línea de
Windows tendrá ^M$ al final de cada línea. Un archivo con
finales de línea de Unix tendrá $ al final de una
línea.
Para convertir el archivo, simplemente ejecuta
dos2unix filename. (De forma contraria, para convertir de
nuevo a formato Windows, puedes ejecutar
unix2dos filename.)
Transferir archivos y carpetas individuales con
scp
Para copiar un archivo individual hacia o desde el clúster, podemos
usar scp (“secure copy”). La sintaxis puede ser un
poco compleja para usuarios nuevos, pero la desglosaremos. El comando
scp es pariente del comando ssh que usamos
para acceder al sistema y puede usar el mismo mecanismo de autenticación
con clave pública.
Para subir a otra computadora, el comando plantilla es
en el que @ y : son separadores de campos y
remote_destination es una ruta relativa a tu directorio
personal remoto, o un nuevo nombre de archivo si deseas cambiarlo, o
tanto una ruta relativa como un nuevo nombre de archivo. Si no
tienes una carpeta específica en mente, puedes omitir
remote_destination y el archivo se copiará a tu directorio
personal en la computadora remota (con su nombre original). Si incluyes
un remote_destination, ten en cuenta que scp
interpreta esto de la misma manera que cp al hacer copias
locales: si existe y es una carpeta, el archivo se copia dentro de la
carpeta; si existe y es un archivo, el archivo se sobrescribe con el
contenido de local_file; si no existe, se asume que es un
nombre de destino para local_file.
Sube el material de la lección a tu directorio personal remoto así:
¿Por qué no descargar directamente en HPC Carpentry’s Cloud Cluster?
La mayoría de los clústeres de computadoras están protegidos del Internet abierto por un firewall. Para mayor seguridad, algunos están configurados para permitir tráfico entrante, pero no saliente. Esto significa que una persona usuaria autenticada puede enviar un archivo a una máquina del clúster, pero una máquina del clúster no puede recuperar archivos desde la máquina de una persona usuaria ni desde Internet abierto.
Intenta descargar el archivo directamente. Ten en cuenta que puede fallar, y ¡está bien!
¿Por qué no descargar directamente en HPC Carpentry’s Cloud Cluster? (continued)
¿Funcionó? Si no, ¿qué muestra la terminal sobre lo que pasó?
Transferir un directorio
Para transferir un directorio completo, añadimos la opción
-r de “recursivo”: esto copia el elemento
especificado, todos los elementos que contiene y todos los elementos de
sus subdirectorios… hasta llegar al final del árbol de directorios que
tiene como raíz la carpeta que indicaste.
Precaución
Para un directorio grande, ya sea por tamaño o número de archivos,
copiar con -r puede tardar mucho en completarse.
Al usar scp, quizá hayas notado que un :
siempre sigue al nombre de la computadora remota. Una cadena
después de : especifica el directorio remoto al
que deseas transferir el archivo o carpeta, incluyendo un nuevo nombre
si deseas renombrar el material remoto. Si dejas este campo en blanco,
scp usa por defecto tu directorio personal y el nombre del
material local a transferir.
En computadoras Linux, / es el separador en rutas de
archivos o directorios. Una ruta que comienza con / se
llama absoluta, ya que no puede haber nada por encima de la
raíz /. Una ruta que no comienza con / se
llama relativa, ya que no está anclada a la raíz.
Si quieres subir un archivo a una ubicación dentro de tu directorio
personal, que suele ser el caso, entonces no necesitas un /
inicial. Después de : puedes escribir la ruta de
destino relativa a tu directorio personal. Si tu directorio personal
es el destino, puedes dejar el campo de destino en blanco o
escribir ~, el atajo para tu directorio personal, por
completitud.
Con scp, una barra final en el directorio de destino es
opcional y no tiene efecto. Una barra final en un directorio de origen
es importante para otros comandos, como rsync.
Una nota sobre rsync
A medida que ganas experiencia transfiriendo archivos, es posible que
el comando scp te resulte limitado. La herramienta rsync proporciona funciones
avanzadas para transferir archivos y normalmente es más rápida que
scp y sftp (ver más abajo). Es especialmente
útil para transferir archivos grandes y/o muchos archivos, y para
sincronizar el contenido de carpetas entre computadoras.
La sintaxis es similar a scp. Para transferir a
otra computadora con las opciones más usadas:
Las opciones son:
-
-a(archivo) para preservar marcas de tiempo, permisos y carpetas, entre otras cosas; implica recursión -
-v(verboso) para obtener salida detallada y ayudar a monitorear la transferencia -
-P(partial/progress) para conservar archivos parcialmente transferidos en caso de interrupción y también mostrar el progreso de la transferencia.
Para copiar un directorio de forma recursiva, podemos usar las mismas opciones:
Tal como está escrito, esto colocará el directorio local y su contenido dentro de tu directorio personal en el sistema remoto. Si se agrega una barra final al origen, no se creará un nuevo directorio correspondiente al directorio transferido, y el contenido del directorio de origen se copiará directamente en el directorio de destino.
Para descargar un archivo, simplemente cambiamos el origen y el destino:
Las transferencias de archivos con scp y
rsync usan SSH para cifrar los datos enviados por la red.
Así que, si puedes conectarte por SSH, podrás transferir archivos. Por
defecto, SSH usa el puerto de red 22. Si se usa un puerto SSH
personalizado, tendrás que especificarlo con la opción adecuada,
frecuentemente -p, -P o --port.
Revisa --help o la página man si no estás
seguro.
BASH
[you@laptop:~]$ man rsync
[you@laptop:~]$ rsync --help | grep port
--port=PORT specify double-colon alternate port number
See http://rsync.samba.org/ for updates, bug reports, and answers
[you@laptop:~]$ rsync --port=768 amdahl.tar.gz yourUsername@cluster.hpc-carpentry.org:(Ten en cuenta que este comando fallará, ya que el puerto correcto en este caso es el predeterminado: 22.)
Transferir archivos de forma interactiva con FileZilla
FileZilla es un cliente multiplataforma para descargar y subir
archivos hacia y desde una computadora remota. Es totalmente a prueba de
fallos y siempre funciona bastante bien. Usa el protocolo
sftp. Puedes leer más sobre el uso del protocolo
sftp en la línea de comandos en la discusión de la lección.
Descarga e instala el cliente FileZilla desde https://filezilla-project.org. Después de instalar y abrir el programa, deberías ver una ventana con un explorador de archivos de tu sistema local en el lado izquierdo de la pantalla. Cuando te conectes al clúster, tus archivos del clúster aparecerán en el lado derecho.
Para conectarte al clúster, solo necesitas ingresar tus credenciales en la parte superior de la pantalla:
- Host:
sftp://cluster.hpc-carpentry.org - User: Tu nombre de usuario del clúster
- Password: Tu contraseña del clúster
- Port: (deja en blanco para usar el puerto predeterminado)
Haz clic en “Quickconnect” para conectar. Deberías ver tus archivos remotos en el lado derecho de la pantalla. Puedes arrastrar y soltar archivos entre el lado izquierdo (local) y el derecho (remoto) de la pantalla para transferirlos.
Por último, si necesitas mover archivos grandes (típicamente mayores
a un gigabyte) de una computadora remota a otra computadora remota,
entra por SSH a la computadora que hospeda los archivos y usa
scp o rsync para transferirlos a la otra. Esto
será más eficiente que usar FileZilla (o aplicaciones relacionadas) que
copiarían desde el origen a tu máquina local y luego a la máquina de
destino.
-
wgetycurl -Odescargan un archivo desde Internet. -
scpyrsynctransfieren archivos hacia y desde tu computadora. - Puedes usar un cliente SFTP como FileZilla para transferir archivos con una GUI.
Content from Ejecutar un trabajo paralelo
Última actualización: 2026-03-31 | Mejora esta página
Hoja de ruta
Preguntas
- ¿Cómo ejecutamos una tarea en paralelo?
- ¿Qué beneficios surgen de la ejecución paralela?
- ¿Cuáles son los límites de las ganancias de la ejecución en paralelo?
Objetivos
- Instalar un paquete de Python usando
pip - Preparar un script de envío de trabajo para el ejecutable paralelo.
- Lanzar trabajos con ejecución paralela.
- Registrar y resumir el tiempo y la precisión de los trabajos.
- Describir la relación entre el paralelismo del trabajo y el rendimiento.
Ahora tenemos las herramientas que necesitamos para ejecutar un trabajo multiprocesador. Este es un aspecto muy importante de los sistemas HPC, ya que el paralelismo es una de las herramientas principales que tenemos para mejorar el rendimiento de las tareas computacionales.
Si se desconectó, vuelva a iniciar sesión en el clúster.
Instalar el Programa Amdahl
Con el código fuente de Amdahl en el clúster, podemos instalarlo, lo
que proporcionará acceso al ejecutable amdahl. Moverse al
directorio extraído, luego use el Instalador de Paquetes para Python, o
pip, para instalarlo en su directorio de inicio
(“usuario”):
Amdahl es Código Python
El programa Amdahl está escrito en Python, e instalarlo o usarlo
requiere ubicando el ejecutable python3 en el nodo de
inicio de sesión. Si no se puede encontrar, intente listar los módulos
disponibles usando module avail, cargue el apropiado e
intente el comando de nuevo.
MPI para Python
El código de Amdahl tiene una dependencia: mpi4py.
Si aún no se ha instalado en el clúster, pip intentará
recopilar mpi4py de Internet e instalarlo para usted. Si esto falla
debido a un firewall unidireccional, debe recuperar mpi4py en su máquina
local y cargarlo, tal como hicimos con Amdahl.
Recuperar y Cargar mpi4py
Si la instalación de Amdahl falló porque no se pudo instalar mpi4py,
recupere el tarball de https://github.com/mpi4py/mpi4py/tarball/master luego
rsync lo al clúster, extraiga e instale:
BASH
[you@laptop:~]$ wget -O mpi4py.tar.gz https://github.com/mpi4py/mpi4py/releases/download/3.1.4/mpi4py-3.1.4.tar.gz
[you@laptop:~]$ scp mpi4py.tar.gz yourUsername@cluster.hpc-carpentry.org:
# or
[you@laptop:~]$ rsync -avP mpi4py.tar.gz yourUsername@cluster.hpc-carpentry.org:BASH
[you@laptop:~]$ ssh yourUsername@cluster.hpc-carpentry.org
[yourUsername@login1 ~]$ tar -xvzf mpi4py.tar.gz # extract the archive
[yourUsername@login1 ~]$ mv mpi4py* mpi4py # rename the directory
[yourUsername@login1 ~]$ cd mpi4py
[yourUsername@login1 ~]$ python3 -m pip install --user .
[yourUsername@login1 ~]$ cd ../amdahl
[yourUsername@login1 ~]$ python3 -m pip install --user .Si pip Genera una
Advertencia…
pip puede advertir que sus binarios de paquete de
usuario no están en su PATH.
ADVERTENCIA
WARNING: The script amdahl is installed in "${HOME}/.local/bin" which is
not on PATH. Consider adding this directory to PATH or, if you prefer to
suppress this warning, use --no-warn-script-location.Para verificar si esta advertencia es un problema, use
which para buscar el programa amdahl:
Si el comando no devuelve ninguna salida y muestra un nuevo
prompt, significa que el archivo amdahl no se ha
encontrado. Debes actualizar la variable de entorno llamada
PATH para incluir la carpeta que falta. Edite su archivo de
configuración de shell de la siguiente manera, luego cierre sesión del
clúster y vuelva a conectarse para que los cambios surtan efecto.
SALIDA
export PATH=${PATH}:${HOME}/.local/binDespués de volver a iniciar sesión en cluster.hpc-carpentry.org,
which debería ser capaz de encontrar amdahl
sin dificultades. Si tuvo que cargar un módulo de Python, cárguelo de
nuevo.
¡Ayuda!
Muchos programas de línea de comandos incluyen un mensaje de “ayuda”.
Pruébelo con amdahl:
SALIDA
usage: amdahl [-h] [-p [PARALLEL_PROPORTION]] [-w [WORK_SECONDS]] [-t] [-e] [-j [JITTER_PROPORTION]]
optional arguments:
-h, --help show this help message and exit
-p [PARALLEL_PROPORTION], --parallel-proportion [PARALLEL_PROPORTION]
Parallel proportion: a float between 0 and 1
-w [WORK_SECONDS], --work-seconds [WORK_SECONDS]
Total seconds of workload: an integer greater than 0
-t, --terse Format output as a machine-readable object for easier analysis
-e, --exact Exactly match requested timing by disabling random jitter
-j [JITTER_PROPORTION], --jitter-proportion [JITTER_PROPORTION]
Random jitter: a float between -1 and +1Este mensaje no nos dice mucho sobre lo que el programa hace, pero sí nos dice las opciones importantes que podríamos querer usar al iniciarlo.
Ejecutar el Trabajo en un Nodo de Cómputo
Cree un archivo de envío (submission file), solicitando una tarea en un solo nodo, luego envíalo.
BASH
#!/bin/bash
#SBATCH -J solo-job
#SBATCH -p cpubase_bycore_b1
#SBATCH -N 1
#SBATCH -n 1
# Load the computing environment we need
module load Python
# Execute the task
amdahlComo antes, use los comandos de estado Slurm para verificar si su trabajo está en ejecución y cuándo se completa:
Use ls para ubicar el archivo de salida. La opción
-t ordena en orden cronológico inverso: el más nuevo
primero. ¿Cuál fue la salida?
La salida del clúster debe escribirse en un archivo en la carpeta desde la cual inició el trabajo. Por ejemplo,
SALIDA
slurm-347087.out serial-job.sh amdahl README.md LICENSE.txtSALIDA
Doing 30.000 seconds of 'work' on 1 processor,
which should take 30.000 seconds with 0.850 parallel proportion of the workload.
Hello, World! I am process 0 of 1 on smnode1. I will do all the serial 'work' for 4.500 seconds.
Hello, World! I am process 0 of 1 on smnode1. I will do parallel 'work' for 25.500 seconds.
Total execution time (according to rank 0): 30.033 secondsComo vimos antes, dos de las opciones del programa
amdahl establecen la cantidad de trabajo y la proporción de
ese trabajo que es de naturaleza paralela. Según la salida, podemos ver
que el código utiliza un valor predeterminado de 30 segundos de trabajo
que es 85% paralelo. El programa se ejecutó durante poco más de 30
segundos en total, y si ejecutamos los números, es cierto que el 15% fue
marcado como ‘serial’ y el 85% como ‘paralelo’.
Dado que solo le dimos al trabajo una CPU, este trabajo no era realmente paralelo: el mismo procesador realizó el trabajo ‘serial’ durante 4.5 segundos, luego la parte ‘paralela’ durante 25.5 segundos, y no se ahorró tiempo. El clúster puede hacerlo mejor, si lo solicitamos.
Ejecutar el Trabajo Paralelo
El programa amdahl utiliza la Interfaz de Paso de
Mensajes (MPI) para el paralelismo – esta es una herramienta común en
los sistemas HPC.
¿Qué es MPI?
La Interfaz de Paso de Mensajes (* Message Passing Interface*) es un conjunto de herramientas que permiten que múltiples tareas que se ejecutan simultáneamente se comuniquen entre sí. Típicamente, un ejecutable único se ejecuta varias veces, posiblemente en diferentes máquinas, y las herramientas de MPI se utilizan para informar a cada instancia del ejectable sobre sus procesos hermanos, y cuál instancia es. MPI también proporciona herramientas para permitir la comunicación entre instancias para coordinar el trabajo, intercambiar información sobre elementos de la tarea o transferir datos. Una instancia de MPI típicamente tiene su propia copia de todas las variables locales.
Aunque los ejecutables que son conscientes de MPI
(MPI-aware) generalmente se pueden ejecutar como programas
independientes, para que se ejecuten en paralelo deben usar un
entorno de tiempo de ejecución de MPI, que es una
implementación específica del estándar de MPI. Para activar el
entorno de MPI, el programa debe iniciarse mediante un comando como
mpiexec (o mpirun, o srun, etc.
dependiendo del tiempo de ejecución de MPI que necesite usar), lo que
garantizará que el soporte de tiempo de ejecución apropiado para el
paralelismo esté incluido.
Argumentos de Tiempo de Ejecución de MPI
Por sí solos, comandos como mpiexec pueden tomar muchos
argumentos especificando cuántas máquinas participarán en la ejecución,
y podría necesitar estos si desea ejecutar un programa MPI en su propio
(por ejemplo, en su computadora portátil). En el contexto de un sistema
de colas, sin embargo, frecuentemente ocurre que el tiempo de ejecución
de MPI obtendrá los parámetros necesarios del sistema de colas,
examinando las variables de entorno establecidas cuando se inicia el
trabajo.
Modifiquemos el script de trabajo para solicitar más núcleos y usar el tiempo de ejecución de MPI.
BASH
[yourUsername@login1 ~]$ cp serial-job.sh parallel-job.sh
[yourUsername@login1 ~]$ nano parallel-job.sh
[yourUsername@login1 ~]$ cat parallel-job.shBASH
#!/bin/bash
#SBATCH -J parallel-job
#SBATCH -p cpubase_bycore_b1
#SBATCH -N 1
#SBATCH -n 4
# Load the computing environment we need
# (mpi4py and numpy are in SciPy-bundle)
module load Python
module load SciPy-bundle
# Execute the task
mpiexec amdahlThen submit your job. Note that the submission command has not really changed from how we submitted the serial job: all the parallel settings are in the batch file rather than the command line.
As before, use the status commands to check when your job runs.
SALIDA
slurm-347178.out parallel-job.sh slurm-347087.out serial-job.sh amdahl README.md LICENSE.txtSALIDA
Doing 30.000 seconds of 'work' on 4 processors,
which should take 10.875 seconds with 0.850 parallel proportion of the workload.
Hello, World! I am process 0 of 4 on smnode1. I will do all the serial 'work' for 4.500 seconds.
Hello, World! I am process 2 of 4 on smnode1. I will do parallel 'work' for 6.375 seconds.
Hello, World! I am process 1 of 4 on smnode1. I will do parallel 'work' for 6.375 seconds.
Hello, World! I am process 3 of 4 on smnode1. I will do parallel 'work' for 6.375 seconds.
Hello, World! I am process 0 of 4 on smnode1. I will do parallel 'work' for 6.375 seconds.
Total execution time (according to rank 0): 10.888 seconds¿Es 4× más rápido?
El trabajo paralelo recibió 4× más procesadores que el trabajo serial: ¿significa que se completó en ¼ del tiempo?
El trabajo paralelo sí tomó menos tiempo: ¡11 segundos es mejor que 30! Pero es solo una mejora de 2.7×, no de 4×.
Mire la salida del trabajo:
- Mientras que el “proceso 0” realizaba trabajo serial, los procesos 1 al 3 realizaban su trabajo paralelo.
- Mientras que el proceso 0 se ponía al día con su trabajo paralelo, el resto no hacía nada en absoluto.
El proceso 0 siempre tiene que terminar su tarea serial antes de poder comenzar con el trabajo paralelo. Esto establece un límite inferior en la cantidad de tiempo que este trabajo tomará, sin importar cuántos núcleos le arroje.
Este es el principio básico detrás de la Ley de Amdahl, que es una forma de predecir mejoras en el tiempo de ejecución para una carga de trabajo fija que puede subdividirse y ejecutarse en paralelo hasta cierto punto.
¿Cuánto Mejora el Rendimiento la Ejecución Paralela?
En teoría, dividir un cálculo perfectamente paralelo entre n procesos de MPI debería producir una disminución en el tiempo de ejecución total por un factor de n. Como hemos visto, los programas reales necesitan algo de tiempo para que los procesos de MPI se comuniquen y coordinen, y algunos tipos de cálculos no se pueden subdividir: solo se ejecutan efectivamente en un solo CPU.
Además, si los procesos de MPI operan en diferentes CPUs físicas en la computadora, o en múltiples nodos de cálculo, se requiere aún más tiempo para la comunicación que cuando todos los procesos operan en un solo CPU.
En la práctica, es común evaluar el paralelismo de un programa de MPI por
- ejecutar el programa en una variedad de números de CPU,
- registrar el tiempo de ejecución en cada ejecución,
- comparando cada tiempo de ejecución con el tiempo cuando se usa una sola CPU.
Puesto que “más es mejor” – la mejora es más fácil de interpretar a partir de aumentos en alguna cantidad que disminuciones – las comparaciones se hacen usando el factor de aceleración S, que se calcula como el tiempo de ejecución de un solo CPU dividido por el tiempo de ejecución de varios CPU. Para un programa perfectamente paralelo, una gráfica de la aceleración S frente al número de CPUs n daría una línea recta, S = n.
Ejecutemos un trabajo más, para que podamos ver cuán cerca de una
línea recta nuestro código amdahl llegue.
BASH
#!/bin/bash
#SBATCH -J parallel-job
#SBATCH -p cpubase_bycore_b1
#SBATCH -N 1
#SBATCH -n 8
# Load the computing environment we need
# (mpi4py and numpy are in SciPy-bundle)
module load Python
module load SciPy-bundle
# Execute the task
mpiexec amdahlThen submit your job. Note that the submission command has not really changed from how we submitted the serial job: all the parallel settings are in the batch file rather than the command line.
As before, use the status commands to check when your job runs.
SALIDA
slurm-347271.out parallel-job.sh slurm-347178.out slurm-347087.out serial-job.sh amdahl README.md LICENSE.txtSALIDA
which should take 7.688 seconds with 0.850 parallel proportion of the workload.
Hello, World! I am process 4 of 8 on smnode1. I will do parallel 'work' for 3.188 seconds.
Hello, World! I am process 0 of 8 on smnode1. I will do all the serial 'work' for 4.500 seconds.
Hello, World! I am process 2 of 8 on smnode1. I will do parallel 'work' for 3.188 seconds.
Hello, World! I am process 1 of 8 on smnode1. I will do parallel 'work' for 3.188 seconds.
Hello, World! I am process 3 of 8 on smnode1. I will do parallel 'work' for 3.188 seconds.
Hello, World! I am process 5 of 8 on smnode1. I will do parallel 'work' for 3.188 seconds.
Hello, World! I am process 6 of 8 on smnode1. I will do parallel 'work' for 3.188 seconds.
Hello, World! I am process 7 of 8 on smnode1. I will do parallel 'work' for 3.188 seconds.
Hello, World! I am process 0 of 8 on smnode1. I will do parallel 'work' for 3.188 seconds.
Total execution time (according to rank 0): 7.697 secondsSalida No Lineal
Cuando ejecutamos el trabajo con 4 trabajadores paralelos, el trabajo serial escribía su salida primero, luego los procesos paralelos escribían su salida, con el proceso 0 viniendo primero y último.
Con 8 trabajadores, este no es el caso: dado que los trabajadores paralelos toman menos tiempo que el trabajo serial, es difícil decir cuál proceso escribirá su salida primero, ¡excepto que no será el proceso 0!
Ahora, resumamos la cantidad de tiempo que tardó cada trabajo en ejecutarse:
| Número de CPUs | Tiempo de Ejecución (seg) |
|---|---|
| 1 | 30.033 |
| 4 | 10.888 |
| 8 | 7.697 |
Luego, use la primera fila para calcular aceleraciones \(S\), usando Python como calculadora de línea de comandos y la fórmula
\[ S(t_{n}) = \frac{t_{1}}{t_{n}} \]
BASH
[yourUsername@login1 ~]$ for n in 30.033 10.888 7.697; do python3 -c "print(30.033 / $n)"; done| Número de CPUs | Aceleración | Ideal |
|---|---|---|
| 1 | 1.0 | 1 |
| 4 | 2.75 | 4 |
| 8 | 3.90 | 8 |
Los archivos de salida del trabajo nos han estado diciendo que este programa está ejecutando el 85% de su trabajo en paralelo, dejando el 15% para ejecutarse en serie. Esto parece razonablemente alto, pero nuestro rápido estudio de aceleración muestra que para obtener una aceleración de 4×, tenemos que usar 8 o 9 procesadores en paralelo. En programas reales, el factor de aceleración está influenciado por
- diseño de CPU
- red de comunicación entre nodos de cálculo
- implementaciones de biblioteca de MPI
- detalles del programa de MPI mismo
Usando la Ley de Amdahl, puede probar que con este programa, es imposible alcanzar una aceleración de 8×, sin importar cuántos procesadores tenga a mano. Los detalles de ese análisis, con resultados que lo respalden, se dejan para la próxima clase en el taller de HPC Carpentry, HPC Workflows.
En un entorno HPC, intentamos reducir el tiempo de ejecución para todos los tipos de trabajos, y MPI es una forma extremadamente común de combinar docenas, cientos o miles de CPUs para resolver un solo problema. Para obtener más información sobre paralelización, consulte la lección de lección para principiantes en paralelo.
- La programación paralela permite que las aplicaciones aprovechen el hardware paralelo.
- El sistema de colas facilita la ejecución de tareas paralelas.
- Las mejoras de rendimiento de la ejecución paralela no se escalan linealmente.
Content from Usar recursos de forma eficaz
Última actualización: 2026-03-31 | Mejora esta página
Hoja de ruta
Preguntas
- ¿Cómo puedo revisar trabajos pasados?
- ¿Cómo puedo usar este conocimiento para crear un script de envío más preciso?
Objetivos
- Consultar estadísticas de trabajos.
- Hacer solicitudes de recursos más precisas en los scripts de trabajo basadas en datos que describen el rendimiento pasado.
Hemos tocado todas las habilidades que necesita para interactuar con un clúster HPC: iniciar sesión por SSH, cargar módulos de software, enviar trabajos paralelos y encontrar la salida. Aprendamos sobre la estimación del uso de recursos y por qué podría importar.
Estimar Recursos Requeridos Usando el Planificador
Aunque ya hablamos sobre cómo solicitar recursos al planificador (scheduler) anteriormente, ¿cómo sabemos qué tipo de recursos necesitará el software en primer lugar, y su demanda de cada uno? En general, a menos que la documentación del software o los testimonios de usuarios proporcionen alguna idea, no sabremos cuánta memoria o tiempo de cómputo necesitará un programa.
Leer la Documentación
La mayoría de los centros HPC mantienen documentación como un wiki, un sitio web o un documento enviado cuando se registra para una cuenta. Eche un vistazo a estos recursos y busque el software que planea usar: alguien podría haber redactado orientación para sacarle el máximo provecho.
Una forma conveniente de averiguar los recursos necesarios para que
un trabajo se ejecute con éxito es enviar un trabajo de prueba, y luego
preguntar al planificador sobre su impacto usando
sacct -u yourUsername. Puede usar este conocimiento para
configurar el siguiente trabajo con una estimación más cercana de su
carga en el sistema. Una buena regla general es solicitar al
planificador entre 20% y 30% más tiempo y memoria de lo que espera que
el trabajo necesite. Esto asegura que pequeñas fluctuaciones en el
tiempo de ejecución o el uso de memoria no resulten en la cancelación de
su trabajo por parte del planificador. Tenga en cuenta que si pide
demasiado, su trabajo podría no ejecutarse aunque haya suficientes
recursos disponibles, porque el planificador estará esperando que los
trabajos de otras personas terminen y liberen los recursos necesarios
para igualar lo que usted pidió.
Estadísticas
Dado que ya enviamos amdahl para ejecutarse en el
clúster, podemos consultar al planificador para ver cuánto tiempo tomó
nuestro trabajo y qué recursos se usaron. Usaremos
sacct -u yourUsername para obtener estadísticas sobre
parallel-job.sh.
SALIDA
JobID JobName Partition Account AllocCPUS State ExitCode
------------ ---------- ---------- ---------- ---------- ---------- --------
7 file.sh cpubase_b+ def-spons+ 1 COMPLETED 0:0
7.batch batch def-spons+ 1 COMPLETED 0:0
7.extern extern def-spons+ 1 COMPLETED 0:0
8 file.sh cpubase_b+ def-spons+ 1 COMPLETED 0:0
8.batch batch def-spons+ 1 COMPLETED 0:0
8.extern extern def-spons+ 1 COMPLETED 0:0
9 example-j+ cpubase_b+ def-spons+ 1 COMPLETED 0:0
9.batch batch def-spons+ 1 COMPLETED 0:0
9.extern extern def-spons+ 1 COMPLETED 0:0Esto muestra todos los trabajos que ejecutamos hoy (note que hay múltiples entradas por trabajo). Para obtener información sobre un trabajo específico (por ejemplo, 347087), cambiamos el comando ligeramente.
Mostrará mucha información; de hecho, cada pieza de información
recopilada sobre su trabajo por el planificador aparecerá aquí. Puede
ser útil redirigir esta información a less para facilitar
su visualización (use las teclas de flecha izquierda y derecha para
desplazarse por los campos).
Discusión
Esta vista puede ayudar a comparar la cantidad de tiempo solicitada y la realmente utilizada, la duración de permanencia en la cola antes del lanzamiento y la huella de memoria en el(los) nodo(s) de cálculo.
¿Qué tan precisas fueron nuestras estimaciones?
Mejorar Solicitudes de Recursos
Del historial de trabajos, vemos que los trabajos amdahl
terminaron de ejecutarse en como mucho unos minutos, una vez
despachados. ¡La estimación de tiempo que proporcionamos en el script de
trabajo fue demasiado larga! Esto hace más difícil para el sistema de
colas estimar con precisión cuándo los recursos quedarán libres para
otros trabajos. En la práctica, esto significa que el sistema de colas
espera para despachar nuestro trabajo amdahl hasta que se
abra el intervalo completo solicitado, en lugar de “colarlo” en una
ventana mucho más corta donde el trabajo podría realmente terminar.
Especificar el tiempo de ejecución esperado en el script de envío con
mayor precisión ayudará a aliviar la congestión del clúster y puede
hacer que su trabajo se despache antes.
Ajustar la Estimación de Tiempo
Edite parallel_job.sh para establecer una mejor
estimación de tiempo. ¿Qué tan cerca puede estar?
Pista: use -t.
- Los scripts de trabajo precisos ayudan al sistema de colas a asignar eficientemente los recursos compartidos.
Content from Usar recursos compartidos de manera responsable
Última actualización: 2026-03-31 | Mejora esta página
Hoja de ruta
Preguntas
- ¿Cómo puedo ser un usuario responsable?
- ¿Cómo puedo proteger mis datos?
- ¿Cómo puedo sacar de mejor manera grandes cantidades de datos de un sistema HPC?
Objetivos
- Describir cómo las acciones de una sola persona pueden afectar la experiencia de otros en un sistema compartido.
- Hablar sobre el comportamiento de un miembro considerado de un sistema compartido.
- Explicar la importancia de respaldar datos críticos.
- Describir los desafíos de transferir grandes cantidades de datos fuera de sistemas HPC.
- Convertir muchos archivos en un solo archivo de tipo archivo usando tar.
Una de las principales diferencias entre usar recursos HPC remotos y su propio sistema (por ejemplo, su computadora portátil) es que los recursos remotos son compartidos. Cuántos usuarios comparten el recurso en un momento dado varía de un sistema a otro, pero es poco probable que usted sea el único usuario conectado o usando un sistema así.
El uso extendido de sistemas de colas donde los usuarios envían trabajos a recursos HPC, es una consecuencia natural de la naturaleza compartida de estos recursos. Hay otras cosas que usted, como un miembro responsable de la comunidad, necesita considerar.
Sea Amable con los Nodos de Acceso
El nodo de acceso suele estar ocupado gestionando a todos los usuarios conectados, creando y editando archivos y compilando software. Si la máquina se queda sin memoria o capacidad de procesamiento, se volverá muy lenta e inutilizable para todos. Aunque la máquina está destinada a usarse, asegúrese de hacerlo responsablemente – de maneras que no afecten negativamente la experiencia de otros usuarios.
Los nodos de acceso son siempre el lugar correcto para lanzar trabajos. Las políticas del clúster varían, pero también pueden usarse para validar flujos de trabajo y, en algunos casos, pueden alojar herramientas avanzadas de depuración o desarrollo específicas del clúster. El clúster puede tener módulos que deben cargarse, posiblemente en un cierto orden, y rutas o versiones de bibliotecas que difieren de su computadora portátil, y realizar una prueba interactiva en el nodo principal es una manera rápida y confiable de descubrir y corregir estos problemas.
Los Nodos de Acceso son un Recurso Compartido
Recuerde, el nodo de acceso se comparte con todos los demás usuarios y sus acciones podrían causar problemas a otras personas. Piense cuidadosamente en las posibles implicaciones de ejecutar comandos que puedan usar grandes cantidades de recursos.
¿No está seguro? Pregunte a su amable administrador de sistemas (“sysadmin”) si lo que está considerando es adecuado para el nodo de acceso, o si hay otro mecanismo para hacerlo de forma segura.
Siempre puede usar los comandos top y ps ux
para listar los procesos que se están ejecutando en el nodo de acceso
junto con la cantidad de CPU y memoria que están usando. Si esta
verificación revela que el nodo de acceso está algo inactivo, puede
usarlo de forma segura para su tarea de procesamiento no rutinaria. Si
algo sale mal -- el proceso tarda demasiado o no responde – puede usar
el comando kill junto con el PID para terminar el
proceso.
Etiqueta del Nodo de Acceso
¿Cuál de estos comandos sería una tarea rutinaria para ejecutar en el nodo de acceso?
python physics_sim.pymakecreate_directories.shmolecular_dynamics_2tar -xzf R-3.3.0.tar.gz
Compilar software, crear directorios y descomprimir software son
tareas comunes y aceptables > para el nodo de acceso: las opciones #2
(make), #3 (mkdir) y #5 (tar)
probablemente están bien. Tenga en cuenta que los nombres de los scripts
no siempre reflejan su contenido: antes de ejecutar la opción #3, por
favor less create_directories.sh y asegúrese de que no sea
un caballo de Troya.
Ejecutar aplicaciones intensivas en recursos está mal visto. A menos
que esté seguro de que no afectará a otros usuarios, no ejecute trabajos
como #1 (python) o #4 (código MD personalizado). Si no está
seguro, pregunte a su amable sysadmin por consejo.
Si experimenta problemas de rendimiento con un nodo de acceso debe reportarlo al personal del sistema (normalmente a través de la mesa de ayuda) para que lo investiguen.
Pruebe Antes de Escalar
Recuerde que generalmente se le cobra por el uso en sistemas compartidos. Un simple error en un script de trabajo puede terminar costando una gran cantidad del presupuesto de recursos. Imagine un script de trabajo con un error que lo hace quedarse sin hacer nada durante 24 horas en 1000 núcleos o uno donde usted solicitó 2000 núcleos por error y solo usa 100 de ellos. Este problema puede agravarse cuando las personas escriben scripts que automatizan el envío de trabajos (por ejemplo, cuando se ejecuta el mismo cálculo o análisis sobre muchos parámetros o archivos diferentes). Cuando esto ocurre perjudica tanto a usted (porque desperdicia muchos recursos cobrados) como a otros usuarios (que quedan bloqueados de acceder a los nodos de cómputo inactivos). En recursos muy ocupados usted puede esperar muchos días en una cola para que su trabajo falle dentro de 10 segundos de iniciarse debido a un error tipográfico trivial en el script de trabajo. ¡Esto es extremadamente frustrante!
La mayoría de los sistemas proporcionan recursos dedicados para pruebas con tiempos de espera cortos para ayudarle a evitar este problema.
Pruebe Scripts de Envío de Trabajos que Usen Grandes Cantidades de Recursos
Antes de enviar una gran corrida de trabajos, envíe uno como prueba primero para asegurarse de que todo funcione como se espera.
Antes de enviar un trabajo muy grande o muy largo, envíe una prueba corta y truncada para asegurarse de que el trabajo inicia como se espera.
Tenga un Plan de Respaldo
Aunque muchos sistemas HPC mantienen respaldos, no siempre cubren todos los sistemas de archivos disponibles y pueden ser solo para propósitos de recuperación ante desastres (es decir, para restaurar todo el sistema de archivos si se pierde, en lugar de un archivo o directorio individual que haya eliminado por error). Proteger datos críticos de corrupción o eliminación es principalmente su responsabilidad: mantenga sus propias copias de respaldo.
Los sistemas de control de versiones (como Git) a menudo tienen opciones gratuitas en la nube (por ejemplo, GitHub y GitLab) que generalmente se usan para almacenar código fuente. Incluso si no está escribiendo sus propios programas, estos pueden ser muy útiles para almacenar scripts de trabajo, scripts de análisis y archivos de entrada pequeños.
Si está construyendo software, puede tener una gran cantidad de código fuente que compila para construir su ejecutable. Dado que estos datos generalmente se pueden recuperar volviendo a descargar el código o volviendo a ejecutar la operación de checkout desde el repositorio de código fuente, estos datos también son menos críticos de proteger.
Para mayores cantidades de datos, especialmente resultados
importantes de sus ejecuciones, que pueden ser irremplazables, debe
asegurarse de tener un sistema robusto para sacar copias de los datos
del sistema HPC siempre que sea posible hacia almacenamiento con
respaldo. Herramientas como rsync pueden ser muy útiles
para esto.
Su acceso al sistema HPC compartido generalmente será de tiempo limitado, por lo que debe asegurarse de tener un plan para transferir sus datos fuera del sistema antes de que su acceso termine. El tiempo requerido para transferir grandes cantidades de datos no debe subestimarse y debe asegurarse de planificar esto con suficiente antelación (idealmente, antes de empezar a usar el sistema para su investigación).
En todos estos casos, la mesa de ayuda del sistema que está usando debería poder proporcionar orientación útil sobre sus opciones de transferencia de datos para los volúmenes de datos que utilizará.
Sus Datos Son Su Responsabilidad
Asegúrese de entender cuál es la política de respaldos en los sistemas de archivos del sistema que está usando y qué implicaciones tiene esto para su trabajo si pierde sus datos en el sistema. Planifique sus respaldos de datos críticos y cómo transferirá datos fuera del sistema a lo largo del proyecto.
Transferir Datos
Como se mencionó anteriormente, muchos usuarios se enfrentan al desafío de transferir grandes cantidades de datos fuera de los sistemas HPC en algún momento (esto es más común en transferir datos hacia afuera que hacia adentro, pero el consejo de abajo aplica en cualquiera de los casos). La velocidad de transferencia de datos puede estar limitada por muchos factores diferentes, por lo que el mejor mecanismo de transferencia de datos a usar depende del tipo de datos que se están transfiriendo y de a dónde van los datos.
Los componentes entre el origen y el destino de sus datos tienen niveles de desempeño variados y, en particular, pueden tener capacidades diferentes con respecto al ancho de banda y la latencia.
El ancho de banda es generalmente la cantidad bruta de datos por unidad de tiempo que un dispositivo es capaz de transmitir o recibir. Es una métrica común y generalmente bien entendida.
La latencia es un poco más sutil. Para las transferencias de datos, puede pensarse como la cantidad de tiempo que toma sacar datos del almacenamiento y ponerlos en una forma transmisible. Los problemas de latencia son la razón por la que se recomienda ejecutar transferencias moviendo un número pequeño de archivos grandes, en lugar de lo contrario.
Algunos de los componentes clave y sus problemas asociados son:
- Velocidad de disco: Los sistemas de archivos en sistemas HPC suelen ser altamente paralelos, consistiendo en una gran cantidad de discos de alto rendimiento. Esto les permite soportar un ancho de banda de datos muy alto. A menos que el sistema remoto tenga un sistema de archivos paralelo similar, puede encontrar que su velocidad de transferencia está limitada por el desempeño del disco en ese extremo.
- Rendimiento de metadatos: Las operaciones de metadatos como abrir y cerrar archivos o listar el propietario o el tamaño de un archivo son mucho menos paralelas que las operaciones de lectura/escritura. Si sus datos consisten en un número muy grande de archivos pequeños puede encontrar que su velocidad de transferencia está limitada por operaciones de metadatos. Las operaciones de metadatos realizadas por otros usuarios del sistema también pueden interactuar fuertemente con las que usted realiza, por lo que reducir el número de tales operaciones que usa (combinando múltiples archivos en un solo archivo) puede reducir la variabilidad en sus tasas de transferencia y aumentar las velocidades de transferencia.
- Velocidad de red: El rendimiento de la transferencia de datos puede estar limitado por la velocidad de red. Más importante aún, está limitado por el tramo más lento de la red entre origen y destino. Si está transfiriendo a su computadora portátil/estación de trabajo, probablemente sea su conexión (ya sea por LAN o WiFi).
- Velocidad del firewall: La mayoría de las redes modernas están protegidas por algún tipo de firewall que filtra el tráfico malicioso. Este filtrado tiene cierta sobrecarga y puede resultar en una reducción del rendimiento de transferencia de datos. Las necesidades de una red de propósito general que aloja servidores de correo/web y equipos de escritorio son muy diferentes a las de una red de investigación que necesita soportar transferencias de datos de alto volumen. Si está tratando de transferir datos hacia o desde un host en una red de propósito general, puede encontrar que el firewall de esa red limitará la tasa de transferencia que puede alcanzar.
Como se mencionó anteriormente, si tiene datos relacionados que
consisten en un gran número de archivos pequeños se recomienda
encarecidamente empaquetar los archivos en un archivo archivo
más grande para almacenamiento y transferencia a largo plazo. Un solo
archivo grande hace un uso más eficiente del sistema de archivos y es
más fácil de mover, copiar y transferir porque se requieren
significativamente menos operaciones de metadatos. Los archivos de
archivo pueden crearse usando herramientas como tar y
zip. Ya vimos tar cuando hablamos sobre
transferencia de datos anteriormente.

Considere la Mejor Manera de Transferir Datos
Si está transfiriendo grandes cantidades de datos, deberá pensar en qué podría afectar su rendimiento de transferencia. Siempre es útil ejecutar algunas pruebas que pueda usar para extrapolar cuánto tiempo tomará transferir sus datos.
Diga que tiene una carpeta “data” que contiene alrededor de 10,000 archivos, una mezcla saludable de datos ASCII y binarios pequeños y grandes. ¿Cuál de las siguientes sería la mejor manera de transferirlos a HPC Carpentry’s Cloud Cluster?
scp -r data yourUsername@cluster.hpc-carpentry.org:~/rsync -ra data yourUsername@cluster.hpc-carpentry.org:~/rsync -raz data yourUsername@cluster.hpc-carpentry.org:~/-
tar -cvf data.tar data;rsync -raz data.tar yourUsername@cluster.hpc-carpentry.org:~/ -
tar -cvzf data.tar.gz data;rsync -ra data.tar.gz yourUsername@cluster.hpc-carpentry.org:~/
-
scpcopiará el directorio de forma recursiva. Esto funciona, pero sin compresión. -
rsync -rafunciona comoscp -r, pero preserva información del archivo como tiempos de creación. Esto es marginalmente mejor. -
rsync -razagrega compresión, lo cual ahorrará algo de ancho de banda. Si tiene una CPU potente en ambos extremos de la línea, y está en una red lenta, esta es una buena opción. - Este comando primero usa
tarpara unir todo en un solo archivo, luegorsync -zpara transferirlo con compresión. Con este gran número de archivos, la sobrecarga de metadatos puede perjudicar su transferencia, así que esto es una buena idea. - Este comando usa
tar -zpara comprimir el archivo, luegorsyncpara transferirlo. Esto puede funcionar de forma similar a #4, pero en la mayoría de los casos (para conjuntos de datos grandes), es la mejor combinación de alto rendimiento y baja latencia (aprovechando al máximo su tiempo y conexión de red).
- Sea cuidadoso con cómo usa el nodo de acceso.
- Sus datos en el sistema son su responsabilidad.
- Planifique y pruebe transferencias de datos grandes.
- A menudo es mejor convertir muchos archivos en un solo archivo de tipo archivo antes de transferir.